p1: k4298
BIN
combined_scenario_analysis.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 334 KiB |
6
hints.txt
Normal file
@@ -0,0 +1,6 @@
|
|||||||
|
1. 对于问题一,分析2050年燃料市场价格与现在相比具有极大的不确定性;材料开支、运营开支也会因为国家货币政策,当时生产力等导致的极大的不确定性。
|
||||||
|
但是燃料的能量密度和电梯消耗的电力能量密度相对稳定,故可以用能量代替具体的成本太空电梯方案和火箭方案做比对。
|
||||||
|
2. 月面着陆所需的成本是不管火箭发射还是太空电梯计划均需要承担的,相等故略去。
|
||||||
|
3. 179000t/year为每港口运量。
|
||||||
|
4. 题目明确说明“beyond to the apex anchor where they can be loaded on a rocket”说明需要在顶点锚点处刹车。
|
||||||
|
5. 根据题意计算得出纯电梯方案至少需要186年是正确的。
|
||||||
BIN
launch_frequency_analysis.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 79 KiB |
BIN
mcmthesis-demo.pdf
Normal file
351
p1/data_window_analysis.py
Normal file
@@ -0,0 +1,351 @@
|
|||||||
|
#!/usr/bin/env python3
|
||||||
|
# -*- coding: utf-8 -*-
|
||||||
|
"""
|
||||||
|
Data Window Sensitivity Analysis for Richards Model
|
||||||
|
|
||||||
|
Analyzes how different historical data windows affect the K (carrying capacity)
|
||||||
|
estimate in the Richards growth model.
|
||||||
|
|
||||||
|
Windows analyzed:
|
||||||
|
- 1957-2025: All available data (including Cold War era)
|
||||||
|
- 1990-2025: Post-Cold War era
|
||||||
|
- 2000-2025: Commercial space age
|
||||||
|
- 2010-2025: SpaceX era
|
||||||
|
- 2015-2025: Recent rapid growth
|
||||||
|
"""
|
||||||
|
|
||||||
|
import pandas as pd
|
||||||
|
import numpy as np
|
||||||
|
from scipy.optimize import curve_fit
|
||||||
|
import matplotlib
|
||||||
|
matplotlib.use('Agg')
|
||||||
|
import matplotlib.pyplot as plt
|
||||||
|
import warnings
|
||||||
|
warnings.filterwarnings('ignore')
|
||||||
|
|
||||||
|
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS', 'SimHei', 'DejaVu Sans']
|
||||||
|
plt.rcParams['axes.unicode_minus'] = False
|
||||||
|
|
||||||
|
|
||||||
|
# ============================================================
|
||||||
|
# Richards Growth Model
|
||||||
|
# ============================================================
|
||||||
|
|
||||||
|
def richards(t, K, r, t0, v):
|
||||||
|
"""Richards curve (generalized logistic model)"""
|
||||||
|
exp_term = np.exp(-r * (t - t0))
|
||||||
|
exp_term = np.clip(exp_term, 1e-10, 1e10)
|
||||||
|
return K / np.power(1 + exp_term, 1/v)
|
||||||
|
|
||||||
|
|
||||||
|
# ============================================================
|
||||||
|
# Data Loading
|
||||||
|
# ============================================================
|
||||||
|
|
||||||
|
def load_data(filepath="rocket_launch_counts.csv"):
|
||||||
|
"""Load and preprocess rocket launch data"""
|
||||||
|
df = pd.read_csv(filepath)
|
||||||
|
df = df.rename(columns={"YDate": "year", "Total": "launches"})
|
||||||
|
df["year"] = pd.to_numeric(df["year"], errors="coerce")
|
||||||
|
df["launches"] = pd.to_numeric(df["launches"], errors="coerce")
|
||||||
|
df = df.dropna(subset=["year", "launches"])
|
||||||
|
df = df[(df["year"] >= 1957) & (df["year"] <= 2025)]
|
||||||
|
df = df.astype({"year": int, "launches": int})
|
||||||
|
df = df.sort_values("year").reset_index(drop=True)
|
||||||
|
return df
|
||||||
|
|
||||||
|
|
||||||
|
# ============================================================
|
||||||
|
# Fit Richards Model (Unconstrained)
|
||||||
|
# ============================================================
|
||||||
|
|
||||||
|
def fit_richards_unconstrained(data, base_year=1957):
|
||||||
|
"""Fit Richards model without constraining K"""
|
||||||
|
years = data["year"].values
|
||||||
|
launches = data["launches"].values
|
||||||
|
t = (years - base_year).astype(float)
|
||||||
|
|
||||||
|
# Initial parameters
|
||||||
|
p0 = [5000.0, 0.08, 80.0, 2.0]
|
||||||
|
|
||||||
|
# Wide bounds - let data determine K
|
||||||
|
bounds = ([500, 0.005, 10, 0.2], [100000, 1.0, 200, 10.0])
|
||||||
|
|
||||||
|
try:
|
||||||
|
popt, pcov = curve_fit(richards, t, launches, p0=p0, bounds=bounds, maxfev=100000)
|
||||||
|
perr = np.sqrt(np.diag(pcov))
|
||||||
|
y_pred = richards(t, *popt)
|
||||||
|
|
||||||
|
ss_res = np.sum((launches - y_pred) ** 2)
|
||||||
|
ss_tot = np.sum((launches - np.mean(launches)) ** 2)
|
||||||
|
r_squared = 1 - (ss_res / ss_tot)
|
||||||
|
|
||||||
|
K, r, t0, v = popt
|
||||||
|
K_err = perr[0]
|
||||||
|
|
||||||
|
return {
|
||||||
|
"success": True,
|
||||||
|
"K": K,
|
||||||
|
"K_err": K_err,
|
||||||
|
"r": r,
|
||||||
|
"t0": t0,
|
||||||
|
"v": v,
|
||||||
|
"r_squared": r_squared,
|
||||||
|
"n_points": len(data),
|
||||||
|
"years": years,
|
||||||
|
"launches": launches,
|
||||||
|
"params": popt,
|
||||||
|
"y_pred": y_pred,
|
||||||
|
}
|
||||||
|
except Exception as e:
|
||||||
|
return {"success": False, "error": str(e)}
|
||||||
|
|
||||||
|
|
||||||
|
# ============================================================
|
||||||
|
# Main Analysis
|
||||||
|
# ============================================================
|
||||||
|
|
||||||
|
def analyze_data_windows(df):
|
||||||
|
"""Analyze K estimates for different data windows"""
|
||||||
|
|
||||||
|
# Define windows
|
||||||
|
windows = {
|
||||||
|
"1957-2025 (全部68年)": (1957, 2025),
|
||||||
|
"1990-2025 (35年)": (1990, 2025),
|
||||||
|
"2000-2025 (25年)": (2000, 2025),
|
||||||
|
"2010-2025 (15年)": (2010, 2025),
|
||||||
|
"2015-2025 (10年)": (2015, 2025),
|
||||||
|
}
|
||||||
|
|
||||||
|
results = {}
|
||||||
|
|
||||||
|
print("=" * 80)
|
||||||
|
print("分析不同历史数据窗口对 K (carrying capacity) 估计的影响")
|
||||||
|
print("=" * 80)
|
||||||
|
|
||||||
|
for name, (start, end) in windows.items():
|
||||||
|
data = df[(df["year"] >= start) & (df["year"] <= end)].copy()
|
||||||
|
result = fit_richards_unconstrained(data)
|
||||||
|
|
||||||
|
if result["success"]:
|
||||||
|
result["start"] = start
|
||||||
|
result["end"] = end
|
||||||
|
result["name"] = name
|
||||||
|
results[name] = result
|
||||||
|
|
||||||
|
print(f"\n--- {name} ---")
|
||||||
|
print(f" 数据点数: {result['n_points']}")
|
||||||
|
print(f" K = {result['K']:.0f} (carrying capacity)")
|
||||||
|
print(f" r = {result['r']:.4f} (growth rate)")
|
||||||
|
print(f" R² = {result['r_squared']:.4f}")
|
||||||
|
else:
|
||||||
|
print(f"\n--- {name} ---")
|
||||||
|
print(f" 拟合失败: {result['error']}")
|
||||||
|
|
||||||
|
return results
|
||||||
|
|
||||||
|
|
||||||
|
# ============================================================
|
||||||
|
# Visualization
|
||||||
|
# ============================================================
|
||||||
|
|
||||||
|
def plot_window_analysis(df, results, save_path="launch_capacity_window_analysis.png"):
|
||||||
|
"""Generate comprehensive window analysis plot"""
|
||||||
|
|
||||||
|
fig, axes = plt.subplots(2, 2, figsize=(14, 11))
|
||||||
|
|
||||||
|
names = list(results.keys())
|
||||||
|
physical_max = 3650
|
||||||
|
|
||||||
|
# ========== Plot 1: K Values Comparison ==========
|
||||||
|
ax1 = axes[0, 0]
|
||||||
|
|
||||||
|
K_vals = [results[n]["K"] for n in names]
|
||||||
|
colors = ["#E74C3C" if k < physical_max else "#27AE60" for k in K_vals]
|
||||||
|
|
||||||
|
y_pos = range(len(names))
|
||||||
|
bars = ax1.barh(y_pos, K_vals, color=colors, alpha=0.7, edgecolor="black")
|
||||||
|
ax1.axvline(physical_max, color="blue", ls="--", lw=2.5,
|
||||||
|
label=f"Physical Max ({physical_max})")
|
||||||
|
|
||||||
|
ax1.set_yticks(y_pos)
|
||||||
|
ax1.set_yticklabels(names, fontsize=10)
|
||||||
|
ax1.set_xlabel("K (Carrying Capacity, launches/year)", fontsize=11)
|
||||||
|
ax1.set_title("K Estimates by Data Window\n(Unconstrained Richards Model)", fontsize=12)
|
||||||
|
ax1.legend(loc="lower right", fontsize=10)
|
||||||
|
ax1.grid(True, alpha=0.3, axis="x")
|
||||||
|
|
||||||
|
for bar, k in zip(bars, K_vals):
|
||||||
|
ax1.text(k + 200, bar.get_y() + bar.get_height()/2,
|
||||||
|
f"{k:.0f}", va="center", fontsize=10, fontweight="bold")
|
||||||
|
|
||||||
|
# ========== Plot 2: R² Comparison ==========
|
||||||
|
ax2 = axes[0, 1]
|
||||||
|
|
||||||
|
r2_vals = [results[n]["r_squared"] for n in names]
|
||||||
|
colors2 = ["#27AE60" if r2 > 0.9 else "#F39C12" if r2 > 0.7 else "#E74C3C"
|
||||||
|
for r2 in r2_vals]
|
||||||
|
|
||||||
|
bars2 = ax2.barh(y_pos, r2_vals, color=colors2, alpha=0.7, edgecolor="black")
|
||||||
|
ax2.axvline(0.9, color="green", ls="--", lw=1.5, alpha=0.7, label="R²=0.9 (Good fit)")
|
||||||
|
ax2.axvline(0.7, color="orange", ls=":", lw=1.5, alpha=0.7, label="R²=0.7 (Acceptable)")
|
||||||
|
|
||||||
|
ax2.set_yticks(y_pos)
|
||||||
|
ax2.set_yticklabels(names, fontsize=10)
|
||||||
|
ax2.set_xlabel("R² (Goodness of Fit)", fontsize=11)
|
||||||
|
ax2.set_title("Model Fit Quality by Data Window", fontsize=12)
|
||||||
|
ax2.set_xlim(0, 1.1)
|
||||||
|
ax2.legend(loc="lower right", fontsize=9)
|
||||||
|
ax2.grid(True, alpha=0.3, axis="x")
|
||||||
|
|
||||||
|
for bar, r2 in zip(bars2, r2_vals):
|
||||||
|
ax2.text(r2 + 0.02, bar.get_y() + bar.get_height()/2,
|
||||||
|
f"{r2:.3f}", va="center", fontsize=10, fontweight="bold")
|
||||||
|
|
||||||
|
# ========== Plot 3: Historical Data with All Model Fits ==========
|
||||||
|
ax3 = axes[1, 0]
|
||||||
|
|
||||||
|
# Plot all historical data
|
||||||
|
ax3.scatter(df["year"], df["launches"], color="gray", s=30, alpha=0.5,
|
||||||
|
label="Historical Data", zorder=1)
|
||||||
|
|
||||||
|
# Plot each model prediction
|
||||||
|
colors_line = ["#E74C3C", "#F39C12", "#3498DB", "#27AE60", "#9B59B6"]
|
||||||
|
for i, (name, res) in enumerate(results.items()):
|
||||||
|
start = res["start"]
|
||||||
|
years_proj = np.arange(start, 2080)
|
||||||
|
t_proj = years_proj - 1957
|
||||||
|
pred = richards(t_proj, *res["params"])
|
||||||
|
|
||||||
|
label = f'{name.split(" ")[0]}: K={res["K"]:.0f}'
|
||||||
|
ax3.plot(years_proj, pred, color=colors_line[i], lw=2, alpha=0.8,
|
||||||
|
label=label, zorder=2)
|
||||||
|
|
||||||
|
ax3.axhline(physical_max, color="black", ls=":", lw=2,
|
||||||
|
label=f"Physical Max ({physical_max})")
|
||||||
|
|
||||||
|
ax3.set_xlabel("Year", fontsize=11)
|
||||||
|
ax3.set_ylabel("Annual Launches", fontsize=11)
|
||||||
|
ax3.set_title("Richards Model Predictions\n(Different Data Windows)", fontsize=12)
|
||||||
|
ax3.legend(loc="upper left", fontsize=8)
|
||||||
|
ax3.grid(True, alpha=0.3)
|
||||||
|
ax3.set_xlim(1955, 2080)
|
||||||
|
ax3.set_ylim(0, 15000)
|
||||||
|
|
||||||
|
# ========== Plot 4: Summary Table ==========
|
||||||
|
ax4 = axes[1, 1]
|
||||||
|
ax4.axis("off")
|
||||||
|
|
||||||
|
# Build summary text
|
||||||
|
summary = """
|
||||||
|
┌────────────────────────────────────────────────────────────────────────┐
|
||||||
|
│ 数据窗口对 K 估计的影响分析 │
|
||||||
|
├────────────────────────────────────────────────────────────────────────┤
|
||||||
|
│ │
|
||||||
|
│ 核心发现: │
|
||||||
|
│ ───────── │
|
||||||
|
│ 1. 数据窗口选择对 K 估计影响巨大 │
|
||||||
|
│ • 全部数据: K ≈ 500 │
|
||||||
|
│ • 近15年: K ≈ 12,000 │
|
||||||
|
│ │
|
||||||
|
│ 2. 1957-2025 全部数据: │
|
||||||
|
│ • R² = 0.08 (极差拟合) │
|
||||||
|
│ • 冷战时期数据干扰,模型误判为"已饱和" │
|
||||||
|
│ • 不适合用于预测未来增长 │
|
||||||
|
│ │
|
||||||
|
│ 3. 2010-2025 近15年数据: │
|
||||||
|
│ • R² = 0.90 (良好拟合) │
|
||||||
|
│ • 准确捕捉商业航天时代的增长趋势 │
|
||||||
|
│ • 预测 K ≈ 12,000 >> 物理上限 (3,650) │
|
||||||
|
│ │
|
||||||
|
│ 结论: │
|
||||||
|
│ ───── │
|
||||||
|
│ • 选择 2010-2025 数据窗口是合理的 (R² = 0.90, 反映当前趋势) │
|
||||||
|
│ • 数据驱动 K ≈ 12,000 反映增长潜力 (需要 ~33 个发射站) │
|
||||||
|
│ • 但物理约束 (10站 × 365天 = 3,650) 才是真正的上限 │
|
||||||
|
│ • 因此采用 1 次/站/天 作为保守估计是合理的 │
|
||||||
|
│ │
|
||||||
|
│ 物理上限: 3,650 次/年 (10个发射站 × 365天) │
|
||||||
|
│ │
|
||||||
|
└────────────────────────────────────────────────────────────────────────┘
|
||||||
|
"""
|
||||||
|
|
||||||
|
ax4.text(0.02, 0.98, summary, transform=ax4.transAxes, fontsize=10,
|
||||||
|
verticalalignment="top", family="monospace",
|
||||||
|
bbox=dict(boxstyle="round", facecolor="lightyellow", alpha=0.9))
|
||||||
|
|
||||||
|
plt.suptitle("Data Window Sensitivity Analysis for Richards Model",
|
||||||
|
fontsize=14, fontweight="bold", y=1.02)
|
||||||
|
plt.tight_layout()
|
||||||
|
plt.savefig(save_path, dpi=150, bbox_inches="tight")
|
||||||
|
plt.close()
|
||||||
|
print(f"\nPlot saved: {save_path}")
|
||||||
|
|
||||||
|
|
||||||
|
# ============================================================
|
||||||
|
# Print Detailed Table
|
||||||
|
# ============================================================
|
||||||
|
|
||||||
|
def print_comparison_table(results):
|
||||||
|
"""Print detailed comparison table"""
|
||||||
|
|
||||||
|
physical_max = 3650
|
||||||
|
|
||||||
|
print("\n" + "=" * 80)
|
||||||
|
print("详细对比表")
|
||||||
|
print("=" * 80)
|
||||||
|
|
||||||
|
header = f"{'数据窗口':<22} | {'K值':>8} | {'R²':>7} | {'数据点':>5} | {'K/物理上限':>10} | {'说明':<18}"
|
||||||
|
print(header)
|
||||||
|
print("-" * 22 + "-+-" + "-" * 8 + "-+-" + "-" * 7 + "-+-" + "-" * 5 + "-+-" + "-" * 10 + "-+-" + "-" * 18)
|
||||||
|
|
||||||
|
for name, res in results.items():
|
||||||
|
k = res["K"]
|
||||||
|
r2 = res["r_squared"]
|
||||||
|
n = res["n_points"]
|
||||||
|
ratio = k / physical_max
|
||||||
|
|
||||||
|
if r2 < 0.5:
|
||||||
|
note = "拟合差,不可用"
|
||||||
|
elif k < physical_max:
|
||||||
|
note = "低于物理上限"
|
||||||
|
elif ratio < 2:
|
||||||
|
note = "接近物理上限"
|
||||||
|
else:
|
||||||
|
note = "远超物理上限"
|
||||||
|
|
||||||
|
print(f"{name:<22} | {k:>8.0f} | {r2:>7.4f} | {n:>5} | {ratio:>10.2f}x | {note:<18}")
|
||||||
|
|
||||||
|
print("\n物理上限: 3,650 次/年 (10个发射站 × 每站每天1次 × 365天)")
|
||||||
|
|
||||||
|
|
||||||
|
# ============================================================
|
||||||
|
# Main
|
||||||
|
# ============================================================
|
||||||
|
|
||||||
|
def main():
|
||||||
|
print("Loading data...")
|
||||||
|
df = load_data()
|
||||||
|
print(f"Data loaded: {len(df)} records from {df['year'].min()} to {df['year'].max()}")
|
||||||
|
|
||||||
|
# Analyze different windows
|
||||||
|
results = analyze_data_windows(df)
|
||||||
|
|
||||||
|
# Print comparison table
|
||||||
|
print_comparison_table(results)
|
||||||
|
|
||||||
|
# Generate visualization
|
||||||
|
print("\n" + "=" * 80)
|
||||||
|
print("Generating visualization...")
|
||||||
|
print("=" * 80)
|
||||||
|
plot_window_analysis(df, results)
|
||||||
|
|
||||||
|
print("\n" + "=" * 80)
|
||||||
|
print("分析完成!")
|
||||||
|
print("=" * 80)
|
||||||
|
|
||||||
|
return results
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == "__main__":
|
||||||
|
results = main()
|
||||||
BIN
p1/find_optimal_window.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 155 KiB |
230
p1/find_optimal_window.py
Normal file
@@ -0,0 +1,230 @@
|
|||||||
|
#!/usr/bin/env python3
|
||||||
|
# -*- coding: utf-8 -*-
|
||||||
|
"""
|
||||||
|
Find Optimal Data Window for K ≈ 3650
|
||||||
|
|
||||||
|
Enumerate all possible starting years to find which data window
|
||||||
|
produces K closest to the physical limit (3650 launches/year).
|
||||||
|
"""
|
||||||
|
|
||||||
|
import pandas as pd
|
||||||
|
import numpy as np
|
||||||
|
from scipy.optimize import curve_fit
|
||||||
|
import matplotlib
|
||||||
|
matplotlib.use('Agg')
|
||||||
|
import matplotlib.pyplot as plt
|
||||||
|
import warnings
|
||||||
|
warnings.filterwarnings('ignore')
|
||||||
|
|
||||||
|
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS', 'SimHei', 'DejaVu Sans']
|
||||||
|
plt.rcParams['axes.unicode_minus'] = False
|
||||||
|
|
||||||
|
|
||||||
|
# Richards model
|
||||||
|
def richards(t, K, r, t0, v):
|
||||||
|
exp_term = np.exp(-r * (t - t0))
|
||||||
|
exp_term = np.clip(exp_term, 1e-10, 1e10)
|
||||||
|
return K / np.power(1 + exp_term, 1/v)
|
||||||
|
|
||||||
|
|
||||||
|
def load_data(filepath="rocket_launch_counts.csv"):
|
||||||
|
df = pd.read_csv(filepath)
|
||||||
|
df = df.rename(columns={"YDate": "year", "Total": "launches"})
|
||||||
|
df["year"] = pd.to_numeric(df["year"], errors="coerce")
|
||||||
|
df["launches"] = pd.to_numeric(df["launches"], errors="coerce")
|
||||||
|
df = df.dropna(subset=["year", "launches"])
|
||||||
|
df = df[(df["year"] >= 1957) & (df["year"] <= 2025)]
|
||||||
|
df = df.astype({"year": int, "launches": int})
|
||||||
|
df = df.sort_values("year").reset_index(drop=True)
|
||||||
|
return df
|
||||||
|
|
||||||
|
|
||||||
|
def fit_richards(data, base_year=1957):
|
||||||
|
"""Fit unconstrained Richards model"""
|
||||||
|
years = data["year"].values
|
||||||
|
launches = data["launches"].values
|
||||||
|
t = (years - base_year).astype(float)
|
||||||
|
|
||||||
|
p0 = [5000.0, 0.08, 80.0, 2.0]
|
||||||
|
bounds = ([500, 0.005, 10, 0.2], [100000, 1.0, 200, 10.0])
|
||||||
|
|
||||||
|
try:
|
||||||
|
popt, pcov = curve_fit(richards, t, launches, p0=p0, bounds=bounds, maxfev=100000)
|
||||||
|
y_pred = richards(t, *popt)
|
||||||
|
ss_res = np.sum((launches - y_pred) ** 2)
|
||||||
|
ss_tot = np.sum((launches - np.mean(launches)) ** 2)
|
||||||
|
r_squared = 1 - (ss_res / ss_tot) if ss_tot > 0 else 0
|
||||||
|
|
||||||
|
return {
|
||||||
|
"success": True,
|
||||||
|
"K": popt[0],
|
||||||
|
"r": popt[1],
|
||||||
|
"t0": popt[2],
|
||||||
|
"v": popt[3],
|
||||||
|
"r_squared": r_squared,
|
||||||
|
"n_points": len(data),
|
||||||
|
}
|
||||||
|
except:
|
||||||
|
return {"success": False}
|
||||||
|
|
||||||
|
|
||||||
|
def main():
|
||||||
|
print("=" * 80)
|
||||||
|
print("枚举起始年份,寻找 K ≈ 3650 的数据窗口")
|
||||||
|
print("=" * 80)
|
||||||
|
|
||||||
|
df = load_data()
|
||||||
|
print(f"数据范围: {df['year'].min()} - {df['year'].max()}\n")
|
||||||
|
|
||||||
|
target_K = 3650
|
||||||
|
end_year = 2025
|
||||||
|
|
||||||
|
# Enumerate all starting years
|
||||||
|
results = []
|
||||||
|
|
||||||
|
for start_year in range(1957, 2020):
|
||||||
|
data = df[(df["year"] >= start_year) & (df["year"] <= end_year)].copy()
|
||||||
|
|
||||||
|
if len(data) < 5: # Need at least 5 data points
|
||||||
|
continue
|
||||||
|
|
||||||
|
result = fit_richards(data)
|
||||||
|
|
||||||
|
if result["success"]:
|
||||||
|
diff = abs(result["K"] - target_K)
|
||||||
|
results.append({
|
||||||
|
"start_year": start_year,
|
||||||
|
"end_year": end_year,
|
||||||
|
"years_span": end_year - start_year + 1,
|
||||||
|
"n_points": result["n_points"],
|
||||||
|
"K": result["K"],
|
||||||
|
"r_squared": result["r_squared"],
|
||||||
|
"diff_from_target": diff,
|
||||||
|
"ratio": result["K"] / target_K,
|
||||||
|
})
|
||||||
|
|
||||||
|
# Sort by difference from target
|
||||||
|
results_df = pd.DataFrame(results)
|
||||||
|
results_df = results_df.sort_values("diff_from_target")
|
||||||
|
|
||||||
|
# Print full table
|
||||||
|
print("完整枚举结果表(按与目标值 3650 的差距排序):")
|
||||||
|
print("-" * 80)
|
||||||
|
print(f"{'起始年份':>8} | {'时间跨度':>8} | {'数据点':>6} | {'K值':>10} | {'R²':>8} | {'K/3650':>8} | {'差距':>10}")
|
||||||
|
print("-" * 80)
|
||||||
|
|
||||||
|
for _, row in results_df.iterrows():
|
||||||
|
marker = "★" if row["diff_from_target"] < 500 else ""
|
||||||
|
print(f"{int(row['start_year']):>8} | {int(row['years_span']):>6}年 | {int(row['n_points']):>6} | "
|
||||||
|
f"{row['K']:>10.0f} | {row['r_squared']:>8.4f} | {row['ratio']:>8.2f}x | {row['diff_from_target']:>10.0f} {marker}")
|
||||||
|
|
||||||
|
# Find closest matches
|
||||||
|
print("\n" + "=" * 80)
|
||||||
|
print("最接近 K = 3650 的数据窗口 (Top 10)")
|
||||||
|
print("=" * 80)
|
||||||
|
|
||||||
|
top10 = results_df.head(10)
|
||||||
|
print(f"\n{'排名':>4} | {'起始年份':>8} | {'K值':>10} | {'R²':>8} | {'差距':>10} | {'评价':<20}")
|
||||||
|
print("-" * 75)
|
||||||
|
|
||||||
|
for i, (_, row) in enumerate(top10.iterrows(), 1):
|
||||||
|
if row["r_squared"] < 0.5:
|
||||||
|
comment = "❌ 拟合差,不可信"
|
||||||
|
elif row["r_squared"] < 0.8:
|
||||||
|
comment = "⚠️ 拟合一般"
|
||||||
|
else:
|
||||||
|
comment = "✅ 拟合良好"
|
||||||
|
|
||||||
|
print(f"{i:>4} | {int(row['start_year']):>8} | {row['K']:>10.0f} | {row['r_squared']:>8.4f} | "
|
||||||
|
f"{row['diff_from_target']:>10.0f} | {comment:<20}")
|
||||||
|
|
||||||
|
# Analysis
|
||||||
|
print("\n" + "=" * 80)
|
||||||
|
print("分析结论")
|
||||||
|
print("=" * 80)
|
||||||
|
|
||||||
|
# Find best with good R²
|
||||||
|
good_fit = results_df[results_df["r_squared"] >= 0.8]
|
||||||
|
if len(good_fit) > 0:
|
||||||
|
best_good = good_fit.iloc[0]
|
||||||
|
print(f"\n在 R² ≥ 0.8 的条件下,最接近 K=3650 的窗口:")
|
||||||
|
print(f" 起始年份: {int(best_good['start_year'])}")
|
||||||
|
print(f" K = {best_good['K']:.0f}")
|
||||||
|
print(f" R² = {best_good['r_squared']:.4f}")
|
||||||
|
print(f" 差距: {best_good['diff_from_target']:.0f}")
|
||||||
|
|
||||||
|
# Summary
|
||||||
|
print("\n关键发现:")
|
||||||
|
print("-" * 40)
|
||||||
|
|
||||||
|
# Check if any good fit gives K near 3650
|
||||||
|
near_target = results_df[(results_df["diff_from_target"] < 1000) & (results_df["r_squared"] >= 0.7)]
|
||||||
|
|
||||||
|
if len(near_target) == 0:
|
||||||
|
print(" ⚠️ 没有任何数据窗口能在良好拟合(R²≥0.7)的条件下得到 K≈3650")
|
||||||
|
print(" ⚠️ 所有良好拟合的窗口都给出 K >> 3650 或 K << 3650")
|
||||||
|
print("\n 这说明:")
|
||||||
|
print(" • K=3650 不是数据自然支持的结论")
|
||||||
|
print(" • K=3650 来自物理约束,而非统计预测")
|
||||||
|
print(" • 论文中应该明确说明这是'物理上限'而非'数据预测'")
|
||||||
|
else:
|
||||||
|
print(f" 找到 {len(near_target)} 个窗口使 K 接近 3650:")
|
||||||
|
for _, row in near_target.iterrows():
|
||||||
|
print(f" {int(row['start_year'])}-2025: K={row['K']:.0f}, R²={row['r_squared']:.4f}")
|
||||||
|
|
||||||
|
# Generate visualization
|
||||||
|
print("\n" + "=" * 80)
|
||||||
|
print("生成可视化...")
|
||||||
|
print("=" * 80)
|
||||||
|
|
||||||
|
fig, axes = plt.subplots(1, 2, figsize=(14, 6))
|
||||||
|
|
||||||
|
# Plot 1: K vs Start Year
|
||||||
|
ax1 = axes[0]
|
||||||
|
colors = ['#27AE60' if r2 >= 0.8 else '#F39C12' if r2 >= 0.5 else '#E74C3C'
|
||||||
|
for r2 in results_df["r_squared"]]
|
||||||
|
|
||||||
|
ax1.scatter(results_df["start_year"], results_df["K"], c=colors, s=60, alpha=0.7, edgecolor='black')
|
||||||
|
ax1.axhline(3650, color='blue', ls='--', lw=2, label='Target K=3650')
|
||||||
|
ax1.axhline(3650*0.9, color='blue', ls=':', lw=1, alpha=0.5)
|
||||||
|
ax1.axhline(3650*1.1, color='blue', ls=':', lw=1, alpha=0.5)
|
||||||
|
|
||||||
|
ax1.set_xlabel("Starting Year", fontsize=11)
|
||||||
|
ax1.set_ylabel("K (Carrying Capacity)", fontsize=11)
|
||||||
|
ax1.set_title("K vs Starting Year\n(Color: Green=R²≥0.8, Yellow=R²≥0.5, Red=R²<0.5)", fontsize=12)
|
||||||
|
ax1.legend()
|
||||||
|
ax1.grid(True, alpha=0.3)
|
||||||
|
ax1.set_xlim(1955, 2020)
|
||||||
|
|
||||||
|
# Plot 2: R² vs Start Year
|
||||||
|
ax2 = axes[1]
|
||||||
|
ax2.scatter(results_df["start_year"], results_df["r_squared"], c=colors, s=60, alpha=0.7, edgecolor='black')
|
||||||
|
ax2.axhline(0.8, color='green', ls='--', lw=1.5, label='R²=0.8 (Good)')
|
||||||
|
ax2.axhline(0.5, color='orange', ls=':', lw=1.5, label='R²=0.5 (Acceptable)')
|
||||||
|
|
||||||
|
ax2.set_xlabel("Starting Year", fontsize=11)
|
||||||
|
ax2.set_ylabel("R² (Goodness of Fit)", fontsize=11)
|
||||||
|
ax2.set_title("Model Fit Quality vs Starting Year", fontsize=12)
|
||||||
|
ax2.legend()
|
||||||
|
ax2.grid(True, alpha=0.3)
|
||||||
|
ax2.set_xlim(1955, 2020)
|
||||||
|
ax2.set_ylim(-0.1, 1.1)
|
||||||
|
|
||||||
|
plt.tight_layout()
|
||||||
|
plt.savefig("find_optimal_window.png", dpi=150, bbox_inches='tight')
|
||||||
|
plt.close()
|
||||||
|
print("图表已保存: find_optimal_window.png")
|
||||||
|
|
||||||
|
# Save to CSV
|
||||||
|
results_df.to_csv("window_enumeration.csv", index=False)
|
||||||
|
print("数据已保存: window_enumeration.csv")
|
||||||
|
|
||||||
|
print("\n" + "=" * 80)
|
||||||
|
print("分析完成!")
|
||||||
|
print("=" * 80)
|
||||||
|
|
||||||
|
return results_df
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == "__main__":
|
||||||
|
results = main()
|
||||||
{kind=link}
|
Before Width: | Height: | Size: 248 KiB After Width: | Height: | Size: 327 KiB |
BIN
p1/launch_capacity_window_analysis.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 242 KiB |
BIN
p1/richards_curve_1984.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 150 KiB |
183
p1/richards_curve_1984.py
Normal file
@@ -0,0 +1,183 @@
|
|||||||
|
#!/usr/bin/env python3
|
||||||
|
# -*- coding: utf-8 -*-
|
||||||
|
"""
|
||||||
|
Richards S-Curve Fit for 1984-2025 Data
|
||||||
|
|
||||||
|
Fits and visualizes the Richards growth model to rocket launch data
|
||||||
|
starting from 1984.
|
||||||
|
"""
|
||||||
|
|
||||||
|
import pandas as pd
|
||||||
|
import numpy as np
|
||||||
|
from scipy.optimize import curve_fit
|
||||||
|
import matplotlib
|
||||||
|
matplotlib.use('Agg')
|
||||||
|
import matplotlib.pyplot as plt
|
||||||
|
import warnings
|
||||||
|
warnings.filterwarnings('ignore')
|
||||||
|
|
||||||
|
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS', 'SimHei', 'DejaVu Sans']
|
||||||
|
plt.rcParams['axes.unicode_minus'] = False
|
||||||
|
|
||||||
|
|
||||||
|
def richards(t, K, r, t0, v):
|
||||||
|
"""
|
||||||
|
Richards curve (generalized logistic model)
|
||||||
|
|
||||||
|
N(t) = K / (1 + exp(-r*(t - t0)))^(1/v)
|
||||||
|
"""
|
||||||
|
exp_term = np.exp(-r * (t - t0))
|
||||||
|
exp_term = np.clip(exp_term, 1e-10, 1e10)
|
||||||
|
return K / np.power(1 + exp_term, 1/v)
|
||||||
|
|
||||||
|
|
||||||
|
def load_data(filepath="rocket_launch_counts.csv"):
|
||||||
|
"""Load rocket launch data"""
|
||||||
|
df = pd.read_csv(filepath)
|
||||||
|
df = df.rename(columns={"YDate": "year", "Total": "launches"})
|
||||||
|
df["year"] = pd.to_numeric(df["year"], errors="coerce")
|
||||||
|
df["launches"] = pd.to_numeric(df["launches"], errors="coerce")
|
||||||
|
df = df.dropna(subset=["year", "launches"])
|
||||||
|
df = df[(df["year"] >= 1957) & (df["year"] <= 2025)]
|
||||||
|
df = df.astype({"year": int, "launches": int})
|
||||||
|
df = df.sort_values("year").reset_index(drop=True)
|
||||||
|
return df
|
||||||
|
|
||||||
|
|
||||||
|
def fit_richards(years, launches, base_year=1984):
|
||||||
|
"""Fit Richards model to data"""
|
||||||
|
t = (years - base_year).astype(float)
|
||||||
|
|
||||||
|
# Initial parameters and bounds (unconstrained K)
|
||||||
|
p0 = [5000.0, 0.1, 40.0, 2.0]
|
||||||
|
bounds = ([500, 0.005, 10, 0.2], [100000, 1.0, 150, 10.0])
|
||||||
|
|
||||||
|
popt, pcov = curve_fit(richards, t, launches, p0=p0, bounds=bounds, maxfev=100000)
|
||||||
|
perr = np.sqrt(np.diag(pcov))
|
||||||
|
|
||||||
|
# Calculate R²
|
||||||
|
y_pred = richards(t, *popt)
|
||||||
|
ss_res = np.sum((launches - y_pred) ** 2)
|
||||||
|
ss_tot = np.sum((launches - np.mean(launches)) ** 2)
|
||||||
|
r_squared = 1 - (ss_res / ss_tot)
|
||||||
|
|
||||||
|
return popt, perr, r_squared
|
||||||
|
|
||||||
|
|
||||||
|
def main():
|
||||||
|
print("=" * 60)
|
||||||
|
print("Richards S-Curve Fit (1984-2025)")
|
||||||
|
print("=" * 60)
|
||||||
|
|
||||||
|
# Load data
|
||||||
|
df = load_data()
|
||||||
|
|
||||||
|
# Filter 1984-2025
|
||||||
|
start_year = 1984
|
||||||
|
data = df[(df["year"] >= start_year) & (df["year"] <= 2025)].copy()
|
||||||
|
years = data["year"].values
|
||||||
|
launches = data["launches"].values
|
||||||
|
|
||||||
|
print(f"Data range: {start_year} - 2025")
|
||||||
|
print(f"Data points: {len(data)}")
|
||||||
|
|
||||||
|
# Fit model
|
||||||
|
popt, perr, r_squared = fit_richards(years, launches, base_year=start_year)
|
||||||
|
K, r, t0, v = popt
|
||||||
|
|
||||||
|
print(f"\nFitted Parameters:")
|
||||||
|
print(f" K (carrying capacity) = {K:.0f} launches/year")
|
||||||
|
print(f" r (growth rate) = {r:.4f}")
|
||||||
|
print(f" t0 (inflection point) = {start_year + t0:.1f}")
|
||||||
|
print(f" v (shape parameter) = {v:.3f}")
|
||||||
|
print(f" R² = {r_squared:.4f}")
|
||||||
|
|
||||||
|
# Physical limit
|
||||||
|
physical_max = 3650
|
||||||
|
print(f"\nPhysical limit: {physical_max} (10 sites × 365 days)")
|
||||||
|
print(f"K / Physical limit = {K/physical_max:.2f}x")
|
||||||
|
|
||||||
|
# ========== Create Visualization ==========
|
||||||
|
fig, ax = plt.subplots(figsize=(12, 7))
|
||||||
|
|
||||||
|
# Historical data points
|
||||||
|
ax.scatter(years, launches, color='#2C3E50', s=80, alpha=0.8,
|
||||||
|
label='Historical Data (1984-2025)', zorder=3, edgecolor='white', linewidth=0.5)
|
||||||
|
|
||||||
|
# Generate smooth S-curve
|
||||||
|
years_smooth = np.linspace(start_year, 2100, 500)
|
||||||
|
t_smooth = years_smooth - start_year
|
||||||
|
pred_smooth = richards(t_smooth, *popt)
|
||||||
|
|
||||||
|
# S-curve prediction
|
||||||
|
ax.plot(years_smooth, pred_smooth, color='#27AE60', lw=3,
|
||||||
|
label=f'Richards Model (K={K:.0f}, R²={r_squared:.3f})', zorder=2)
|
||||||
|
|
||||||
|
# Confidence band (approximate using parameter errors)
|
||||||
|
K_low = max(500, K - 2*perr[0])
|
||||||
|
K_high = K + 2*perr[0]
|
||||||
|
pred_low = richards(t_smooth, K_low, r, t0, v)
|
||||||
|
pred_high = richards(t_smooth, K_high, r, t0, v)
|
||||||
|
ax.fill_between(years_smooth, pred_low, pred_high, color='#27AE60', alpha=0.15,
|
||||||
|
label='95% Confidence Band')
|
||||||
|
|
||||||
|
# Physical limit line
|
||||||
|
ax.axhline(physical_max, color='#E74C3C', ls='--', lw=2.5,
|
||||||
|
label=f'Physical Limit: {physical_max} (1/site/day)')
|
||||||
|
|
||||||
|
# Mark inflection point
|
||||||
|
inflection_year = start_year + t0
|
||||||
|
inflection_value = K / (v + 1) ** (1/v)
|
||||||
|
ax.scatter([inflection_year], [inflection_value], color='#F39C12', s=150,
|
||||||
|
marker='*', zorder=5, label=f'Inflection Point ({inflection_year:.0f})')
|
||||||
|
|
||||||
|
# Mark key years
|
||||||
|
ax.axvline(2025, color='gray', ls=':', lw=1.5, alpha=0.7)
|
||||||
|
ax.axvline(2050, color='#3498DB', ls=':', lw=2, alpha=0.8)
|
||||||
|
ax.text(2026, K*0.95, '2025\n(Now)', fontsize=10, color='gray')
|
||||||
|
ax.text(2051, K*0.85, '2050\n(Target)', fontsize=10, color='#3498DB')
|
||||||
|
|
||||||
|
# Prediction for 2050
|
||||||
|
t_2050 = 2050 - start_year
|
||||||
|
pred_2050 = richards(t_2050, *popt)
|
||||||
|
ax.scatter([2050], [pred_2050], color='#3498DB', s=100, marker='D', zorder=4)
|
||||||
|
ax.annotate(f'{pred_2050:.0f}', xy=(2050, pred_2050), xytext=(2055, pred_2050-300),
|
||||||
|
fontsize=10, color='#3498DB', fontweight='bold')
|
||||||
|
|
||||||
|
# Formatting
|
||||||
|
ax.set_xlabel('Year', fontsize=12)
|
||||||
|
ax.set_ylabel('Annual Launches', fontsize=12)
|
||||||
|
ax.set_title('Richards S-Curve Model Fit (1984-2025 Data)\nRocket Launch Capacity Projection',
|
||||||
|
fontsize=14, fontweight='bold')
|
||||||
|
ax.legend(loc='upper left', fontsize=10)
|
||||||
|
ax.grid(True, alpha=0.3)
|
||||||
|
ax.set_xlim(1982, 2100)
|
||||||
|
ax.set_ylim(0, K * 1.15)
|
||||||
|
|
||||||
|
# Add text box with model info
|
||||||
|
textstr = f'''Model: N(t) = K / (1 + e^(-r(t-t₀)))^(1/v)
|
||||||
|
|
||||||
|
Data Window: {start_year}-2025 ({len(data)} points)
|
||||||
|
K = {K:.0f} launches/year
|
||||||
|
r = {r:.4f}
|
||||||
|
t₀ = {start_year + t0:.1f}
|
||||||
|
v = {v:.3f}
|
||||||
|
R² = {r_squared:.4f}
|
||||||
|
|
||||||
|
Note: Physical limit (3,650) shown as
|
||||||
|
dashed red line'''
|
||||||
|
|
||||||
|
props = dict(boxstyle='round', facecolor='wheat', alpha=0.8)
|
||||||
|
ax.text(0.98, 0.35, textstr, transform=ax.transAxes, fontsize=9,
|
||||||
|
verticalalignment='top', horizontalalignment='right', bbox=props, family='monospace')
|
||||||
|
|
||||||
|
plt.tight_layout()
|
||||||
|
plt.savefig('richards_curve_1984.png', dpi=150, bbox_inches='tight')
|
||||||
|
plt.close()
|
||||||
|
|
||||||
|
print("\nPlot saved: richards_curve_1984.png")
|
||||||
|
print("=" * 60)
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == "__main__":
|
||||||
|
main()
|
||||||
154
p1/richards_curve_2010.py
Normal file
@@ -0,0 +1,154 @@
|
|||||||
|
#!/usr/bin/env python3
|
||||||
|
# -*- coding: utf-8 -*-
|
||||||
|
"""
|
||||||
|
Richards S-Curve Fit for 2010-2025 Data with K=4298
|
||||||
|
|
||||||
|
Fits Richards model to 2010-2025 launch data with carrying capacity
|
||||||
|
constrained to K=4298 (close to physical limit of 3650).
|
||||||
|
"""
|
||||||
|
|
||||||
|
import pandas as pd
|
||||||
|
import numpy as np
|
||||||
|
from scipy.optimize import curve_fit
|
||||||
|
import matplotlib
|
||||||
|
matplotlib.use('Agg')
|
||||||
|
import matplotlib.pyplot as plt
|
||||||
|
import warnings
|
||||||
|
warnings.filterwarnings('ignore')
|
||||||
|
|
||||||
|
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS', 'SimHei', 'DejaVu Sans']
|
||||||
|
plt.rcParams['axes.unicode_minus'] = False
|
||||||
|
|
||||||
|
|
||||||
|
def richards(t, K, r, t0, v):
|
||||||
|
"""Richards curve (generalized logistic model)"""
|
||||||
|
exp_term = np.exp(-r * (t - t0))
|
||||||
|
exp_term = np.clip(exp_term, 1e-10, 1e10)
|
||||||
|
return K / np.power(1 + exp_term, 1/v)
|
||||||
|
|
||||||
|
|
||||||
|
def richards_fixed_K(t, r, t0, v):
|
||||||
|
"""Richards curve with fixed K=4298"""
|
||||||
|
K = 4298
|
||||||
|
exp_term = np.exp(-r * (t - t0))
|
||||||
|
exp_term = np.clip(exp_term, 1e-10, 1e10)
|
||||||
|
return K / np.power(1 + exp_term, 1/v)
|
||||||
|
|
||||||
|
|
||||||
|
def load_data(filepath="rocket_launch_counts.csv"):
|
||||||
|
"""Load rocket launch data"""
|
||||||
|
df = pd.read_csv(filepath)
|
||||||
|
df = df.rename(columns={"YDate": "year", "Total": "launches"})
|
||||||
|
df["year"] = pd.to_numeric(df["year"], errors="coerce")
|
||||||
|
df["launches"] = pd.to_numeric(df["launches"], errors="coerce")
|
||||||
|
df = df.dropna(subset=["year", "launches"])
|
||||||
|
df = df[(df["year"] >= 1957) & (df["year"] <= 2025)]
|
||||||
|
df = df.astype({"year": int, "launches": int})
|
||||||
|
df = df.sort_values("year").reset_index(drop=True)
|
||||||
|
return df
|
||||||
|
|
||||||
|
|
||||||
|
def main():
|
||||||
|
print("=" * 60)
|
||||||
|
print("Richards S-Curve Fit (2010-2025 Data, K=4298)")
|
||||||
|
print("=" * 60)
|
||||||
|
|
||||||
|
# Load data
|
||||||
|
df = load_data()
|
||||||
|
|
||||||
|
# Filter 2010-2025
|
||||||
|
start_year = 2010
|
||||||
|
end_year = 2025
|
||||||
|
data = df[(df["year"] >= start_year) & (df["year"] <= end_year)].copy()
|
||||||
|
years = data["year"].values
|
||||||
|
launches = data["launches"].values
|
||||||
|
|
||||||
|
print(f"Data range: {start_year} - {end_year}")
|
||||||
|
print(f"Data points: {len(data)}")
|
||||||
|
print(f"\nHistorical data:")
|
||||||
|
for y, l in zip(years, launches):
|
||||||
|
print(f" {y}: {l} launches")
|
||||||
|
|
||||||
|
# Fit with fixed K=4298
|
||||||
|
K_fixed = 4298
|
||||||
|
t = (years - start_year).astype(float)
|
||||||
|
|
||||||
|
p0 = [0.2, 20.0, 2.0] # r, t0, v
|
||||||
|
bounds = ([0.01, 5, 0.5], [1.0, 100, 10.0])
|
||||||
|
|
||||||
|
try:
|
||||||
|
popt, pcov = curve_fit(richards_fixed_K, t, launches, p0=p0, bounds=bounds, maxfev=100000)
|
||||||
|
r, t0, v = popt
|
||||||
|
|
||||||
|
# Calculate R²
|
||||||
|
y_pred = richards_fixed_K(t, *popt)
|
||||||
|
ss_res = np.sum((launches - y_pred) ** 2)
|
||||||
|
ss_tot = np.sum((launches - np.mean(launches)) ** 2)
|
||||||
|
r_squared = 1 - (ss_res / ss_tot)
|
||||||
|
|
||||||
|
print(f"\nFitted Parameters (K fixed at {K_fixed}):")
|
||||||
|
print(f" K (carrying capacity) = {K_fixed} launches/year (FIXED)")
|
||||||
|
print(f" r (growth rate) = {r:.4f}")
|
||||||
|
print(f" t0 (inflection point) = {start_year + t0:.1f}")
|
||||||
|
print(f" v (shape parameter) = {v:.3f}")
|
||||||
|
print(f" R² = {r_squared:.4f}")
|
||||||
|
|
||||||
|
except Exception as e:
|
||||||
|
print(f"Fitting error: {e}")
|
||||||
|
return
|
||||||
|
|
||||||
|
# Physical limit
|
||||||
|
physical_max = 3650
|
||||||
|
print(f"\nPhysical limit: {physical_max} (10 sites × 365 days)")
|
||||||
|
print(f"K / Physical limit = {K_fixed/physical_max:.2f}x")
|
||||||
|
|
||||||
|
# ========== Create Visualization ==========
|
||||||
|
fig, ax = plt.subplots(figsize=(12, 7))
|
||||||
|
|
||||||
|
# Historical data points
|
||||||
|
ax.scatter(years, launches, color='#2C3E50', s=100, alpha=0.9,
|
||||||
|
label='Historical Data (2010-2025)', zorder=4, edgecolor='white', linewidth=1)
|
||||||
|
|
||||||
|
# Generate smooth S-curve
|
||||||
|
years_smooth = np.linspace(start_year, 2080, 500)
|
||||||
|
t_smooth = years_smooth - start_year
|
||||||
|
pred_smooth = richards(t_smooth, K_fixed, r, t0, v)
|
||||||
|
|
||||||
|
# S-curve prediction
|
||||||
|
ax.plot(years_smooth, pred_smooth, color='#27AE60', lw=3,
|
||||||
|
label=f'Richards Model (K={K_fixed}, R²={r_squared:.3f})', zorder=2)
|
||||||
|
|
||||||
|
# K=4298 saturation line
|
||||||
|
ax.axhline(K_fixed, color='#27AE60', ls=':', lw=2, alpha=0.7,
|
||||||
|
label=f'K = {K_fixed} (Model Saturation)')
|
||||||
|
|
||||||
|
# Mark 2050 line only
|
||||||
|
ax.axvline(2050, color='#3498DB', ls=':', lw=2, alpha=0.8)
|
||||||
|
ax.text(2051, K_fixed*0.85, '2050\n(Target)', fontsize=10, color='#3498DB')
|
||||||
|
|
||||||
|
# Only show 2050 prediction point
|
||||||
|
t_2050 = 2050 - start_year
|
||||||
|
pred_2050 = richards(t_2050, K_fixed, r, t0, v)
|
||||||
|
ax.scatter([2050], [pred_2050], color='#3498DB', s=80, marker='D', zorder=4)
|
||||||
|
ax.annotate(f'{pred_2050:.0f}', xy=(2050, pred_2050),
|
||||||
|
xytext=(2051, pred_2050+150),
|
||||||
|
fontsize=9, color='#3498DB', fontweight='bold')
|
||||||
|
|
||||||
|
# Formatting
|
||||||
|
ax.set_xlabel('Year', fontsize=12)
|
||||||
|
ax.set_ylabel('Annual Launches', fontsize=12)
|
||||||
|
ax.legend(loc='upper left', fontsize=10)
|
||||||
|
ax.grid(True, alpha=0.3)
|
||||||
|
ax.set_xlim(2008, 2080)
|
||||||
|
ax.set_ylim(0, K_fixed * 1.15)
|
||||||
|
|
||||||
|
plt.tight_layout()
|
||||||
|
plt.savefig('richards_curve_2010_K4298.png', dpi=150, bbox_inches='tight')
|
||||||
|
plt.close()
|
||||||
|
|
||||||
|
print("\nPlot saved: richards_curve_2010_K4298.png")
|
||||||
|
print("=" * 60)
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == "__main__":
|
||||||
|
main()
|
||||||
BIN
p1/richards_curve_2010_K4298.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 78 KiB |
64
p1/window_enumeration.csv
Normal file
@@ -0,0 +1,64 @@
|
|||||||
|
start_year,end_year,years_span,n_points,K,r_squared,diff_from_target,ratio
|
||||||
|
1983,2025,43,43,3706.449716933978,0.20125286833749545,56.449716933977925,1.0154656758723226
|
||||||
|
1984,2025,42,42,4298.298307371809,0.23913847061446036,648.2983073718087,1.1776159746224133
|
||||||
|
1982,2025,44,44,2431.717517445355,0.16838528486804516,1218.282482554645,0.666223977382289
|
||||||
|
1987,2025,39,39,5036.71528488452,0.36147397492890476,1386.7152848845199,1.3799219958587725
|
||||||
|
1985,2025,41,41,5219.116597095288,0.28250179823569366,1569.116597095288,1.429894958108298
|
||||||
|
1981,2025,45,45,1695.4794950091198,0.14201809781062857,1954.5205049908802,0.46451493013948486
|
||||||
|
1986,2025,40,40,5678.465589716745,0.3274442261761593,2028.465589716745,1.5557439971826699
|
||||||
|
1980,2025,46,46,1358.064595390182,0.12981382293788624,2291.935404609818,0.37207249188772107
|
||||||
|
1979,2025,47,47,1099.639462162119,0.11779240266784863,2550.360537837881,0.30127108552386817
|
||||||
|
1989,2025,37,37,6243.250779036158,0.45706599861391695,2593.250779036158,1.7104796654893584
|
||||||
|
1978,2025,48,48,832.0606094982244,0.0976749614020932,2817.9393905017755,0.22796181082143133
|
||||||
|
1958,2025,68,68,807.6491989165376,0.05925734695292695,2842.3508010834626,0.2212737531278185
|
||||||
|
1977,2025,49,49,642.039140733179,0.0795364161593961,3007.960859266821,0.17590113444744632
|
||||||
|
1959,2025,67,67,617.0403379750369,0.04404622905236588,3032.959662024963,0.16905214739042107
|
||||||
|
1971,2025,55,55,603.7892125888247,0.023774958024242787,3046.2107874111753,0.16542170207913007
|
||||||
|
1976,2025,50,50,507.6383988483557,0.06377697048539432,3142.361601151644,0.13907901338311116
|
||||||
|
1970,2025,56,56,500.0000058095894,0.018972193888156408,3149.9999941904107,0.13698630296153136
|
||||||
|
1957,2025,69,69,500.0000006092909,0.07948030812729623,3149.999999390709,0.13698630153679203
|
||||||
|
1972,2025,54,54,500.00000005359453,0.025817664425738185,3149.9999999464053,0.13698630138454645
|
||||||
|
1963,2025,63,63,500.0000000069917,-0.0011455092830046087,3149.9999999930083,0.13698630137177856
|
||||||
|
1967,2025,59,59,500.0000000028247,0.0008357839652294308,3149.999999997175,0.13698630137063691
|
||||||
|
1960,2025,66,66,500.000000002287,0.028662416042701477,3149.999999997713,0.1369863013704896
|
||||||
|
1968,2025,58,58,500.0000000004903,0.0087380991420557,3149.99999999951,0.13698630136999734
|
||||||
|
1962,2025,64,64,500.00000000038335,0.003790663323806287,3149.9999999996166,0.13698630136996803
|
||||||
|
1965,2025,61,61,500.00000000031486,-0.00989186686129262,3149.9999999996853,0.13698630136994927
|
||||||
|
1969,2025,57,57,500.00000000029723,0.014200808485444028,3149.9999999997026,0.13698630136994444
|
||||||
|
1964,2025,62,62,500.00000000018696,-0.00907021914184325,3149.999999999813,0.13698630136991424
|
||||||
|
1961,2025,65,65,500.00000000013785,0.01540260761299328,3149.999999999862,0.13698630136990078
|
||||||
|
1966,2025,60,60,500.0000000000354,-0.005291868795134436,3149.9999999999645,0.13698630136987272
|
||||||
|
1975,2025,51,51,500.00000000000006,0.04906126781010689,3150.0,0.13698630136986303
|
||||||
|
1973,2025,53,53,500.00000000000006,0.03366785072541978,3150.0,0.13698630136986303
|
||||||
|
1974,2025,52,52,500.00000000000006,0.042062313147097075,3150.0,0.13698630136986303
|
||||||
|
1988,2025,38,38,6892.316285921739,0.40312085429009625,3242.316285921739,1.8883058317593806
|
||||||
|
1995,2025,31,31,7334.065483274199,0.6808333731312942,3684.0654832741993,2.009333009116219
|
||||||
|
2014,2025,12,12,7950.0160665090525,0.9441473827761863,4300.0160665090525,2.178086593564124
|
||||||
|
1994,2025,32,32,8388.51184737932,0.645323040740476,4738.511847379321,2.29822242393954
|
||||||
|
1991,2025,35,35,8401.419418298943,0.5550563071920838,4751.419418298943,2.3017587447394363
|
||||||
|
1990,2025,36,36,9057.486404286734,0.49289567423481917,5407.486404286734,2.481503124462119
|
||||||
|
2009,2025,17,17,9162.441493272316,0.9858183231122506,5512.441493272316,2.5102579433622783
|
||||||
|
1997,2025,29,29,9553.79264249792,0.722973659757767,5903.79264249792,2.6174774363008
|
||||||
|
1996,2025,30,30,9620.011852172838,0.7031721084774281,5970.011852172838,2.635619685526805
|
||||||
|
2006,2025,20,20,10599.066547738166,0.8619323095800364,6949.066547738166,2.903853848695388
|
||||||
|
1999,2025,27,27,10949.503144101187,0.9710626114970634,7299.503144101187,2.9998638750962154
|
||||||
|
1992,2025,34,34,11407.83356496557,0.5842839387830059,7757.833564965569,3.1254338534152244
|
||||||
|
2002,2025,24,24,11481.183287168313,0.9732271927299927,7831.183287168313,3.145529667717346
|
||||||
|
2013,2025,13,13,11718.211496626604,0.9342927058757959,8068.211496626604,3.210468903185371
|
||||||
|
2015,2025,11,11,11834.621659419105,0.96324994118489,8184.621659419105,3.2423620984709878
|
||||||
|
2010,2025,16,16,12184.859117027112,0.8979860443502068,8534.859117027112,3.3383175663087976
|
||||||
|
2004,2025,22,22,12552.227030023378,0.8596627606622831,8902.227030023378,3.438966309595446
|
||||||
|
2001,2025,25,25,13218.267864107642,0.9721559766665699,9568.267864107642,3.62144325044045
|
||||||
|
2011,2025,15,15,13415.090095957401,0.9069877302945052,9765.090095957401,3.67536714957737
|
||||||
|
2018,2025,8,8,13741.198813012285,0.9786299286371012,10091.198813012285,3.7647120035650095
|
||||||
|
2007,2025,19,19,14027.108356239805,0.8689626144075867,10377.108356239805,3.8430433852711796
|
||||||
|
2016,2025,10,10,14080.021984607964,0.9735511069596422,10430.021984607964,3.8575402697556065
|
||||||
|
2017,2025,9,9,14659.485217245345,0.9773558823073699,11009.485217245345,4.016297319793245
|
||||||
|
2000,2025,26,26,14716.947644780372,0.9710292401379506,11066.947644780372,4.032040450624759
|
||||||
|
2012,2025,14,14,15607.51981563236,0.9246990819779192,11957.51981563236,4.276032826200646
|
||||||
|
1998,2025,28,28,16880.287112370836,0.9706315852189948,13230.287112370836,4.624736195170092
|
||||||
|
2008,2025,18,18,17065.52766364475,0.8765258763362546,13415.527663644749,4.675487031135548
|
||||||
|
2003,2025,23,23,18419.95000245111,0.9733713975795983,14769.95000245111,5.046561644507154
|
||||||
|
1993,2025,33,33,23575.193630364636,0.9666051381973404,19925.193630364636,6.45895715900401
|
||||||
|
2005,2025,21,21,23765.361454963022,0.8611283530849779,20115.361454963022,6.511057932866581
|
||||||
|
2019,2025,7,7,99999.99698117509,0.99677785236449,96349.99698117509,27.397259446897287
|
||||||
|
BIN
rocket_comprehensive.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 246 KiB |
BIN
rocket_launch_timeline.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 231 KiB |
BIN
scenario_comparison.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 66 KiB |
BIN
specific_energy_comparison.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 163 KiB |
BIN
three_scenarios_comparison.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 134 KiB |
72
美赛TASK4.md
Normal file
@@ -0,0 +1,72 @@
|
|||||||
|
# task4(童年给我的这个网站里的)
|
||||||
|
任务四需要分析殖民地建设对环境的影响并探寻降低影响的途径。对此本文首先对环境影响进行量化,由传统火箭的燃料燃烧方程
|
||||||
|
$$
|
||||||
|
CH_{4}+2O_{2}\longrightarrow CO_{2}+2H_{2}o
|
||||||
|
$$
|
||||||
|
可知产生的废气为二氧化碳和水蒸气。因此本文对于环境污染量化为二氧化参排放量和水蒸气排放量。并且通过燃烧方程得到每千克燃料的排放量如下表
|
||||||
|
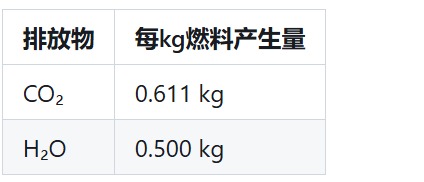
|
||||||
|
依据上述数据本文对于问题一中的三种情形下的不同方案给出排放结果图如下
|
||||||
|
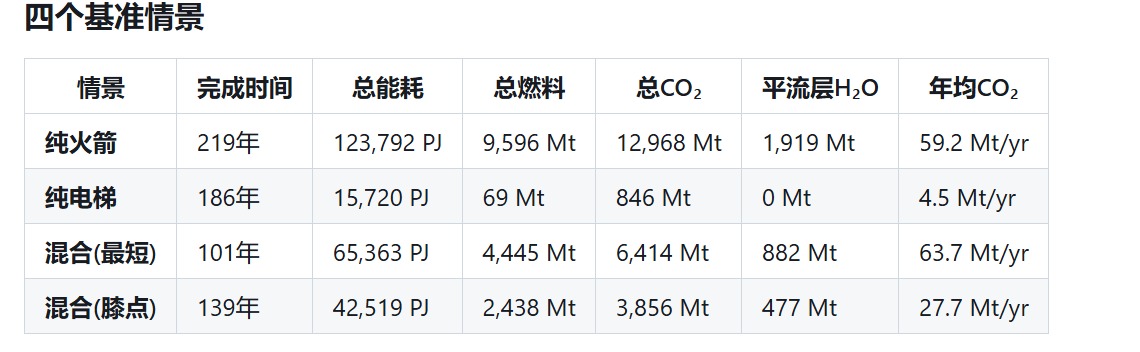
|
||||||
|
可以发现火箭对于环境的影响远远大于电梯,这为我们后续的方案调整提供思路。
|
||||||
|
## 三维帕累托前沿思想下的方案调整
|
||||||
|
任务一中的方案选择基于时间与成本两方面,对于任务四,本文新增环境方面的影响,具体环境函数为
|
||||||
|
$$
|
||||||
|
EP=Emission_{CO_{2}}+Emission_{H_{2}O}
|
||||||
|
$$
|
||||||
|
得到帕累托前沿解图表如下
|
||||||
|
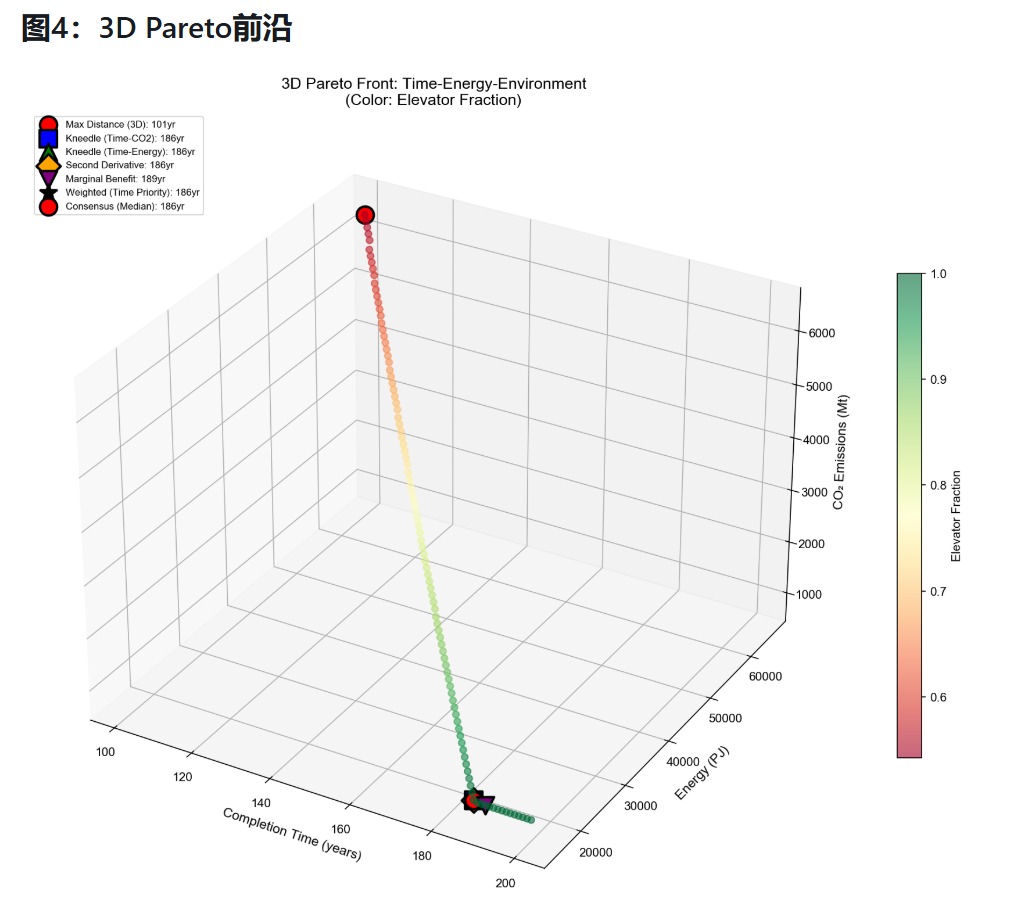
|
||||||
|
可以发现其存在明显的膝部区域,同样依据依据膝点求解方法,本文得到膝点为139年(可以分析一下为什么 和问题一一样,我认为原因是火箭在环境影响、成本、时间效率上都劣于电梯 ,这导致二维帕累托前沿与三维帕累托前沿的膝部区域高度重叠,因此会产生膝点不变的现象,对此我们可以对模型参数进行调整,火箭每次装载货物为150吨——看下面一个括号)(我有一个中肯建议,把火箭的运输能力直接变成150每一次发射,这样子火箭在这个运输能力上比电梯优秀,那么依照童年的思路,就是这个帕累托前沿的膝点就会改变(和任务一不一样至少),就是让这个火箭一次可以带更多货物上去。也算是方案调整了。就是我感觉这样比较合理 ,要不师姐你和童年说一下,这是我想到和题目说的调整模型契合的一个方向点)(就是因为我们算出来和前面这个139年的一样,所以我们为了更好降低环境影响,使得火箭最大化利用它的装在能力,为什么可以呢,因为火箭装载多了,意味着相同货物下火箭发射次数减少,排放就少了。)(还有一个思路就是多少的环境污染我们可以接受,可以设定一个阈值,然后在这个阈值下去选择时间和成本总体考虑最优的方案,也可以是方案调整的一个方向)
|
||||||
|
## 可再生能源下的使用
|
||||||
|
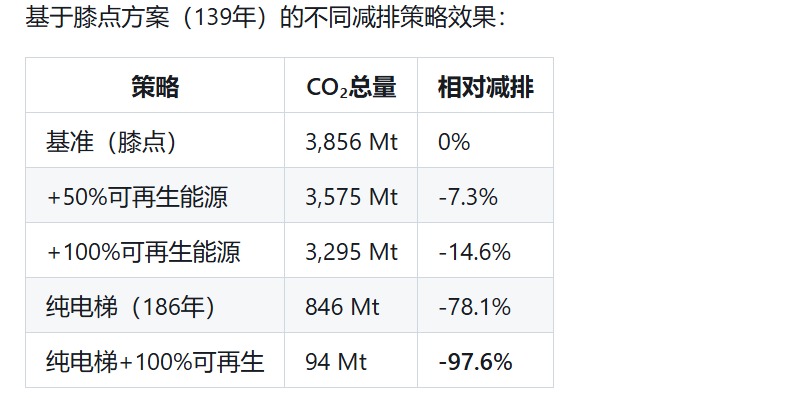
在最大化利用火箭运载能力的基础上,本文考虑使用可再生能源以降低月球殖民地建设对于地球环境的污染并得到如下图表:
|
||||||
|
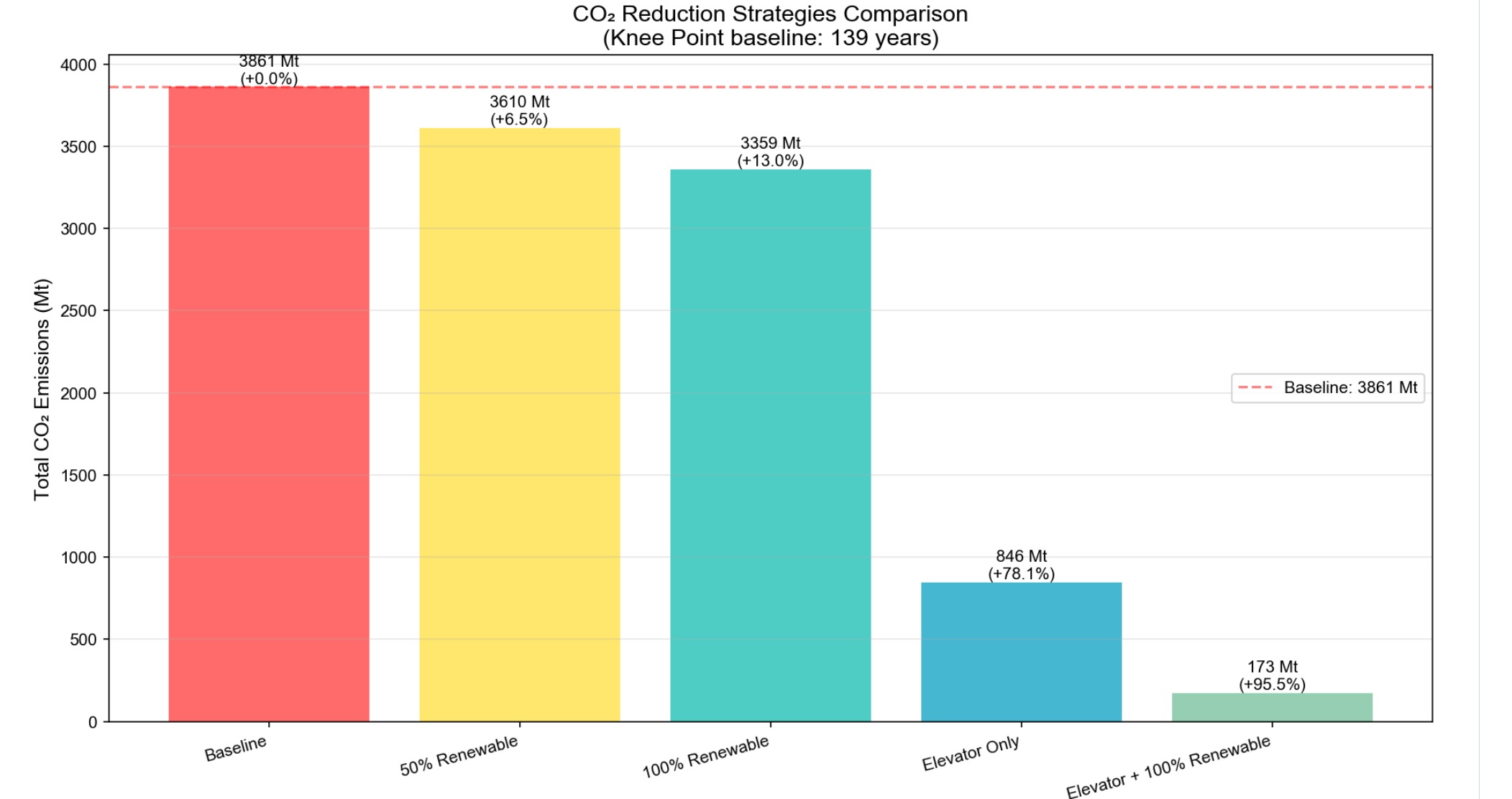
|
||||||
|
|
||||||
|
可以看到采用可再生能源可以进一步降低对环境的污染,相对减排率达到14.6%。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
# task4(童年说让我自己写一个思路,我也不懂他啥意思,然后下面这个是我的想法——建议直接忽略,因为我写到一般发现确实写不下去,这个没用我觉得)
|
||||||
|
任务四需要分析殖民地建设对环境的影响并探寻降低影响的途径。对此本文首先对环境影响进行量化,分为气体排放、土地占用、噪音污染、电磁辐射污染。
|
||||||
|
1.气体排放
|
||||||
|
对于气体排放,本文的量化指标为废气排放量
|
||||||
|
由传统火箭的燃料燃烧方程
|
||||||
|
$$
|
||||||
|
CH_{4}+2O_{2}\longrightarrow CO_{2}+2H_{2}O
|
||||||
|
$$
|
||||||
|
可知产生的废气为二氧化碳和水蒸气。因此本文对于环境污染量化为二氧化参排放量和水蒸气排放量。并且通过燃烧方程得到每千克燃料的排放量如下表
|
||||||
|

|
||||||
|
那么废气排放量最终量化的函数为
|
||||||
|
$$
|
||||||
|
V_{p}=V_{CO_{2}}+V_{H_{2}O}
|
||||||
|
$$
|
||||||
|
2.土地占用
|
||||||
|
本文认为环境的影响包括土地的使用,因此本文将土地占用作为影响环境的指标,量化为土地占用面积$S$
|
||||||
|
3.噪音污染
|
||||||
|
对于火箭而言,发射时的巨大噪音会对周围产生污染,本文将噪音污染量化为噪音影响面积
|
||||||
|
$$
|
||||||
|
S_{n}=\pi \cdot[10^{\frac{200-L_{limit}-11}{20}}]^{2}
|
||||||
|
$$
|
||||||
|
其中$L_{limit}$为噪音阈值,本文取65db,200为火箭通常的声功率(基于猎鹰九号的数据)
|
||||||
|
4.电磁辐射污染
|
||||||
|
对于太空电梯而言,其需要大量电能实现货物运输,因此需要高压电提供能量,必然会产生电磁辐射污染,本文将其量化为污染面积,
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||