# Task 1: 2021年MFP访问计划——需求驱动的频次分配与日历排程
## 摘要
本文提出一套**因果逻辑清晰、闭环可审计**的2021年MFP访问频次分配与日历排程方案。核心创新点:
1. **截断回归修正**:识别到9个站点历史服务量 $\mu_i > 250$(最高396.6),说明高需求站点的观测数据被容量截断,采用截断正态模型恢复真实需求 $\tilde{\mu}_i$
2. **质量加权有效性**:考虑高服务量下每户分配食物减少的质量折扣
3. **满足率公平性**:以"年度服务量/真实需求"的均等程度衡量公平,而非简单的访问次数均等
方案遵循四阶段结构:需求估计 → 频次分配 → 效果评估 → 日历排程。
---
## 整体流程图
### Mermaid版本(GitHub可渲染)
```mermaid
flowchart TB
subgraph INPUT["数据输入"]
A[data.xlsx
70站点数据]
end
subgraph TASK1["TASK 1: 基础排程"]
direction TB
subgraph CORE["核心流程 ✅ 已完成"]
B1[01_clean.py
数据清洗]
B2[02_demand_correction.py
截断回归修正]
B3[03_allocate.py
Hamilton分配]
B4[04_evaluate.py
指标计算]
B5[05_schedule.py
日历排程]
B1 --> B2 --> B3 --> B4
B3 --> B5
end
subgraph VALIDATE["结果验证 ✅ 已完成"]
V1[06_validate.py
约束检验]
V2[07_backtest.py
历史回测]
end
subgraph SENSITIVITY["敏感性分析 ✅ 已完成"]
S1[08_sensitivity.py
参数扫描]
end
subgraph VISUAL["可视化 ✅ 已完成"]
P1[09_visualize.py
图表生成]
end
CORE --> VALIDATE
CORE --> SENSITIVITY
VALIDATE --> VISUAL
SENSITIVITY --> VISUAL
end
subgraph TASK2["TASK 2: 天气响应 ⏳"]
C1[2a或2b方案]
end
subgraph TASK3["TASK 3: 双站点同车 ⏳"]
D1[共生站点优化]
end
subgraph TASK4["TASK 4: Executive Summary ⏳"]
E1[1页执行摘要]
end
A --> B1
VISUAL --> TASK2
VISUAL --> TASK3
TASK2 --> TASK4
TASK3 --> TASK4
style CORE fill:#90EE90
style VALIDATE fill:#90EE90
style SENSITIVITY fill:#90EE90
style VISUAL fill:#90EE90
```
### ASCII版本(详细)
```
┌─────────────────────────────────────────────────────────────────────────────────────────┐
│ TASK 1 完整流程 │
├─────────────────────────────────────────────────────────────────────────────────────────┤
│ │
│ ┌─────────────────────────────────────────────────────────────────────────────────┐ │
│ │ 核心流程 [已完成 ✓] │ │
│ │ │ │
│ │ data.xlsx ──▶ 01_clean ──▶ 02_demand ──▶ 03_allocate ──▶ 04_evaluate │ │
│ │ correction │ │ │
│ │ ▼ │ │
│ │ 05_schedule │ │
│ └─────────────────────────────────────────────────────────────────────────────────┘ │
│ │ │ │
│ ┌─────────────┴────────────┬───────────┴───────────┐ │
│ ▼ ▼ ▼ │
│ ┌──────────────────────┐ ┌──────────────────────┐ ┌──────────────────────┐ │
│ │ 结果验证 [已完成 ✓] │ │ 敏感性分析 [已完成 ✓] │ │ 可视化 [已完成 ✓] │ │
│ │ │ │ │ │ │ │
│ │ 06_validate.py │ │ 08_sensitivity.py │ │ 09_visualize.py │ │
│ │ ┌──────────────────┐ │ │ ┌──────────────────┐ │ │ ┌──────────────────┐ │ │
│ │ │✓ 约束满足检验 │ │ │ │✓ C ∈ {350..450} │ │ │ │✓ 站点地图(需求) │ │ │
│ │ │ - Σk=730 ✓ │ │ │ │✓ p阈值扫描 │ │ │ │✓ k分布直方图 │ │ │
│ │ │ - k≥1 ✓ │ │ │ │✓ C̄ ∈ {200..300}│ │ │ │✓ E-F权衡曲线 │ │ │
│ │ │ - 每日2站点 ✓ │ │ │ │ │ │ │ │✓ 日历热力图 │ │ │
│ │ └──────────────────┘ │ │ └──────────────────┘ │ │ │✓ 间隔分布箱线图 │ │ │
│ │ │ │ │ │ └──────────────────┘ │ │
│ │ 07_backtest.py │ │ 结论: │ │ │ │
│ │ ┌──────────────────┐ │ │ E1变化 < 1.3% │ │ 输出: │ │
│ │ │✓ 2019数据回测 │ │ │ 模型稳健 │ │ figures/*.png │ │
│ │ │✓ 预测vs实际对比 │ │ │ │ │ (7张图) │ │
│ │ │✓ 残差分析 │ │ │ │ │ │ │
│ │ └──────────────────┘ │ │ │ │ │ │
│ └──────────────────────┘ └──────────────────────┘ └──────────────────────┘ │
│ │ │
└────────────────────────────────────────┼───────────────────────────────────────────────┘
│
▼
┌────────────────────┴────────────────────┐
│ │
▼ ▼
┌──────────────────────────┐ ┌──────────────────────────┐
│ TASK 2: 天气响应 [待完成] │ │ TASK 3: 双站点 [待完成] │
└──────────────────────────┘ └──────────────────────────┘
│ │
└────────────────┬────────────────────────┘
▼
┌──────────────────────────┐
│ TASK 4: 执行摘要 [待完成] │
└──────────────────────────┘
```
### 当前进度与待完成事项
| 模块 | 状态 | 脚本 | 说明 |
|------|------|------|------|
| 数据清洗 | ✅ 完成 | `01_clean.py` | 字段标准化 |
| 需求修正 | ✅ 完成 | `02_demand_correction.py` | 截断回归 |
| 频次分配 | ✅ 完成 | `03_allocate.py` | Hamilton方法 |
| 指标计算 | ✅ 完成 | `04_evaluate.py` | E1,E2,F1,F2 |
| 日历排程 | ✅ 完成 | `05_schedule.py` | 贪心+局部优化 |
| 约束验证 | ✅ 完成 | `06_validate.py` | 6项硬约束全部通过 |
| 历史回测 | ✅ 完成 | `07_backtest.py` | 模型有效性验证 |
| 敏感性分析 | ✅ 完成 | `08_sensitivity.py` | 参数稳健性检验 |
| 可视化 | ✅ 完成 | `09_visualize.py` | 7张论文图表 |
---
## 运行结果摘要
| 指标 | 推荐方案 | 均匀分配 | 2019缩放 | 变化 |
|------|---------|---------|---------|------|
| E1 (总服务量) | **140,121** | 104,797 | 104,071 | +34.6% |
| E2 (质量加权) | **131,673** | 101,309 | 100,264 | +31.3% |
| F1 (Gini系数) | 0.314 | **0.026** | 0.092 | 公平性降低 |
| F2 (最低满足率) | 2.0 | **8.4** | 5.0 | - |
**核心发现**:按需求比例分配可提升34.6%的总服务量,但存在有效性-公平性权衡。
---
## 1. 问题形式化
### 1.1 输入数据
| 字段 | 符号 | 说明 |
|------|------|------|
| 位置 | $(lat_i, lon_i)$ | 经纬度坐标 |
| 2019年访问次数 | $v_i$ | 历史频次,总计722次 |
| 单次服务人数均值 | $\mu_i$ | 观测均值,范围[17.2, 396.6] |
| 单次服务人数标准差 | $\sigma_i$ | 观测波动,范围[2.2, 93.5] |
### 1.2 运营参数
| 参数 | 值 | 来源 |
|------|-----|------|
| 卡车物理运力 | 15,000 lbs | 题面明确 |
| 典型服务户数 | [200, 250] | 题面"typical" |
| 每日可派车次 | 2 | 题面 |
| 年度总访问次数 $N$ | 730 | $365 \times 2$ |
### 1.3 硬约束
$$\sum_{i=1}^{70} k_i = 730 \tag{C1: 资源约束}$$
$$k_i \geq 1 \tag{C2: 覆盖约束}$$
$$|\text{sites on day } t| = 2 \tag{C3: 每日容量}$$
---
## 2. 阶段一:真实需求估计(截断回归)
### 2.1 问题本质:为什么需要修正?
**底层逻辑**:
题面说"typical visit serves 200-250 families",但数据中 $\mu_{max} = 396.6$。这说明:
1. **200-250不是硬上限**:高需求站点可以服务更多家庭
2. **存在隐性容量约束**:卡车运力15000磅 ÷ 每户约38-75磅 ≈ 200-400户
3. **观测被截断**:当真实需求 > 容量时,只能观测到容量值
```
真实需求分布: 观测到的分布:
│ │
│ ╱╲ │ ╱╲
│ ╱ ╲ │ ╱ ╲▓▓▓ ← 被截断部分
│ ╱ ╲ │ ╱ │
│ ╱ ╲ │ ╱ │
├───────────── ├───────┤
0 μ̃ C 0 μ C
```
**因此**:直接用 $\mu_i$ 会**系统性低估**高需求站点的真实需求。
### 2.2 截断概率的推导
**假设**:真实需求 $\tilde{D}_i \sim \mathcal{N}(\tilde{\mu}_i, \sigma_i^2)$
**推导**:截断概率 = 真实需求超过容量C的概率
$$p_i^{trunc} = P(\tilde{D}_i > C) = P\left(Z > \frac{C - \tilde{\mu}_i}{\sigma_i}\right) = 1 - \Phi\left(\frac{C - \tilde{\mu}_i}{\sigma_i}\right)$$
**近似**:由于我们不知道 $\tilde{\mu}_i$,用观测值 $\mu_i$ 近似:
$$p_i^{trunc} \approx 1 - \Phi\left(\frac{C - \mu_i}{\sigma_i}\right)$$
**物理意义**:$p_i^{trunc}$ 越大,说明该站点越可能被截断,需要更大的修正。
### 2.3 修正公式的推导
**截断正态的条件期望**(Mills ratio):
对于 $X \sim \mathcal{N}(\mu, \sigma^2)$,有:
$$E[X | X > c] = \mu + \sigma \cdot \frac{\phi\left(\frac{c-\mu}{\sigma}\right)}{1 - \Phi\left(\frac{c-\mu}{\sigma}\right)}$$
**简化近似**:
当截断概率 $p^{trunc}$ 较小时,修正量近似与 $p^{trunc}$ 线性相关:
$$\tilde{\mu}_i \approx \mu_i \cdot (1 + \alpha \cdot p_i^{trunc})$$
取 $\alpha = 0.4$(经验系数,可通过敏感性分析调整)。
**分段处理的原因**:
- 当 $p^{trunc} < 0.02$:截断概率很低,修正量可忽略
- 当 $p^{trunc} \geq 0.02$:存在显著截断,需要修正
### 2.4 实际修正结果
| site_id | 站点名称 | $\mu$ | $\sigma$ | $p^{trunc}$ | $\tilde{\mu}$ | 修正幅度 |
|---------|---------|-------|----------|-------------|---------------|----------|
| 66 | MFP Waverly | 396.6 | 51.9 | 0.474 | 471.9 | +19.0% |
| 2 | MFP Avoca | 314.6 | 57.3 | 0.068 | 323.2 | +2.7% |
| 13 | MFP College TC3 | 261.5 | 92.0 | 0.066 | 268.4 | +2.6% |
| 17 | MFP Endwell | 285.2 | 60.8 | 0.030 | 288.6 | +1.2% |
| 30 | MFP Redeemer | 230.6 | 93.5 | 0.035 | 233.8 | +1.4% |
---
## 3. 阶段二:频次分配模型
### 3.1 分配原则的底层逻辑
**题面要求**:"frequency informed by total demand in surrounding communities"
**问题**:什么是"周边社区需求"?
**两种理解**:
1. ❌ 用空间核平滑估计(循环论证:用供给估计需求)
2. ✅ 每个站点本身就服务其周边社区,$\tilde{\mu}_i$ 就是需求代理
**我们的选择**:直接用修正后的 $\tilde{\mu}_i$ 作为"周边社区需求"的代理。
**为什么按比例分配?**
假设目标是**最大化总服务量**且**保证公平**:
- 最大化 $\sum k_i \mu_i$ subject to $\sum k_i = N$
- 拉格朗日条件:$\frac{\partial}{\partial k_i}(k_i \mu_i - \lambda k_i) = \mu_i - \lambda = 0$
这说明最优解是 $k_i \propto \mu_i$(或 $\tilde{\mu}_i$)。
### 3.2 为什么用Hamilton方法?
**问题**:按比例分配得到的是实数,需要转换为整数。
**Hamilton方法(最大余数法)的优点**:
1. **保证总和**:$\sum k_i = N$ 严格成立
2. **公平性**:余数大的站点优先获得额外1次
3. **可解释**:政治选举中广泛使用,逻辑透明
**替代方法对比**:
| 方法 | 优点 | 缺点 |
|------|------|------|
| 四舍五入 | 简单 | 总和可能不等于N |
| 向下取整+贪心 | 简单 | 可能不公平 |
| Hamilton | 公平、总和准确 | 稍复杂 |
| 整数规划 | 可加约束 | 过于复杂 |
### 3.3 分配结果验证
- 总访问次数:$\sum k_i = 730$ ✓
- 访问次数范围:$[2, 32]$
- 覆盖约束:$\min k_i = 2 \geq 1$ ✓
---
## 4. 阶段三:效果评估指标
### 4.1 有效性指标的设计逻辑
**E1:原始总服务量**
$$E_1 = \sum_{i=1}^{70} k_i \cdot \mu_i$$
**问题**:E1假设服务量与访问次数线性增长,但忽略了**质量下降**。
**E2:质量加权服务量**
**底层逻辑**:当 $\mu_i > 250$ 时,每户获得的食物量下降。
$$\text{每户食物量} = \frac{15000 \text{ lbs}}{\mu_i}$$
当 $\mu_i = 250$ 时,每户60磅(典型值)。
当 $\mu_i = 400$ 时,每户37.5磅(低于典型)。
**质量折扣因子**:
$$q(\mu) = \min\left(1, \frac{250}{\mu}\right) = \begin{cases} 1 & \mu \leq 250 \\ \frac{250}{\mu} & \mu > 250 \end{cases}$$
**物理意义**:$q(\mu)$ 表示"相对于典型服务质量的比例"。
### 4.2 公平性指标的设计逻辑
**为什么不用"访问次数相等"衡量公平?**
题面说"are some served much better than others"——关键词是**served**,不是**visited**。
需求100的站点访问10次 vs 需求200的站点访问10次 → 后者服务不足。
**满足率的定义**:
$$r_i = \frac{\text{年度服务量}}{\text{年度需求}} = \frac{k_i \cdot \mu_i}{\tilde{\mu}_i}$$
**为什么用Gini系数?**
- Gini系数是衡量分布不均等的标准指标
- 取值[0,1],0表示完全均等,1表示完全不均等
- 易于解释:收入分配、资源分配广泛使用
### 4.3 评估结果
| 方案 | E1 | E2 | F1 (Gini) | F2 (min r) |
|------|-----|-----|-----------|------------|
| **推荐方案** | **140,121** | **131,673** | 0.314 | 2.00 |
| 均匀分配 | 104,797 | 101,309 | **0.026** | **8.41** |
| 2019缩放 | 104,071 | 100,264 | 0.092 | 5.00 |
**有效性-公平性权衡**:
```
F1 (Gini, 越小越公平)
▲
0.4 │ ● 推荐方案 (E1=140k)
│
0.3 │
│
0.2 │
│
0.1 │ ● 2019缩放 (E1=104k)
│
0.0 │● 均匀分配 (E1=105k)
└────────────────────────────▶ E1 (总服务量)
100k 120k 140k
```
---
## 5. 阶段四:日历排程
### 5.1 排程目标的底层逻辑
**为什么要均匀分布访问日期?**
题面说"schedule published months in advance to help clients plan"。
如果某站点访问间隔不均匀(如:1月5次,2月0次),客户难以规划。
**理想间隔**:
$$\Delta_i^* = \frac{365}{k_i}$$
例如:$k_i = 12$ 次/年 → 理想间隔 ≈ 30天/次
### 5.2 贪心算法的设计逻辑
**为什么不用整数规划?**
730个访问事件 × 365天 = 26万个0-1变量,计算复杂度过高。
**贪心策略**:
1. 为每个访问事件计算"理想日期"
2. 按理想日期排序
3. 依次分配到最近的可用槽位
**为什么有效?**
- 理想日期已经考虑了均匀分布
- 按顺序分配避免了冲突
- 局部优化可进一步改善
### 5.3 排程结果
- 365天全部满载 ✓
- 平均间隔:55.4天
- 最大间隔:179天(低频站点)
---
## 6. 结果验证 ✅
### 6.1 约束满足检验 (`06_validate.py`)
| 检验项 | 公式 | 结果 |
|--------|------|------|
| C1: 资源约束 | $\sum k_i = 730$ | ✅ 通过 |
| C2: 覆盖约束 | $\min k_i \geq 1$ | ✅ 通过 (min=2) |
| C3: 日容量约束 | 每日恰好2站点 | ✅ 通过 |
| C4: 无重复约束 | 同一天不重复访问同一站点 | ✅ 通过 |
| C5: 排程一致性 | 排程次数 = k_i | ✅ 通过 |
| C6: 总天数 | 日历天数 = 365 | ✅ 通过 |
**结论**:所有6项硬约束全部通过。
### 6.2 模型有效性验证 (`07_backtest.py`)
**关键发现**:
| 指标 | 值 | 解读 |
|------|-----|------|
| corr(visits_2019, μ) | 0.0352 | 2019年访问次数与需求弱相关 |
| corr(visits_2019, μ̃) | 0.0433 | 历史分配未充分考虑需求 |
| CV(k/μ̃) | 0.0523 | k与μ̃高度成正比,模型内部一致 |
| 服务量改进 | +35.24% | 相比2019缩放方案 |
**结论**:2019年历史分配与需求几乎不相关(r=0.035),说明历史分配未按需求进行。推荐方案实现按需分配,服务量提升35%。
---
## 7. 敏感性分析 ✅
### 7.1 参数扫描 (`08_sensitivity.py`)
| 参数 | 基准值 | 扫描范围 | 影响 |
|------|--------|---------|------|
| 有效容量 $C$ | 400 | [350, 375, 400, 425, 450] | 截断修正强度 |
| 截断阈值 $p^{trunc}$ | 0.02 | [0.01, 0.02, 0.05, 0.10] | 修正站点数 |
| 质量阈值 $\bar{C}$ | 250 | [200, 225, 250, 275, 300] | E2计算 |
### 7.2 敏感性分析结果
本节基于 `08_sensitivity.xlsx`(含 `sensitivity_C / sensitivity_p_thresh / sensitivity_c_bar / combo_scan / baseline` 等工作表)对**效率(E1/E2)**与**公平性(F1/F2/F3)**的变化做更细致解读。数值默认四舍五入展示。
**基准结果(C=400, p_thresh=0.02, $\bar{C}=250$)**:
| 指标 | 值 | 解读 |
|------|----|------|
| 修正站点数 | 5 | 发生截断修正的站点数量 |
| E1 | 140,121 | 总服务量 $\sum k_i\mu_i$ |
| E2 | 131,673 | 质量加权服务量 $\sum k_i\mu_i q(\mu_i)$ |
| F1 (Gini) | 0.3140 | 满足率分布不均衡程度(越小越公平) |
| F2 (min r) | 2.00 | 最低满足率(本次扫描恒为2) |
| F3 (CV of r) | 0.5569 | 满足率变异系数(越小越均衡) |
| 频次范围 | k_min=2, k_max=32 | 头部频次(k_max)反映资源集中度 |
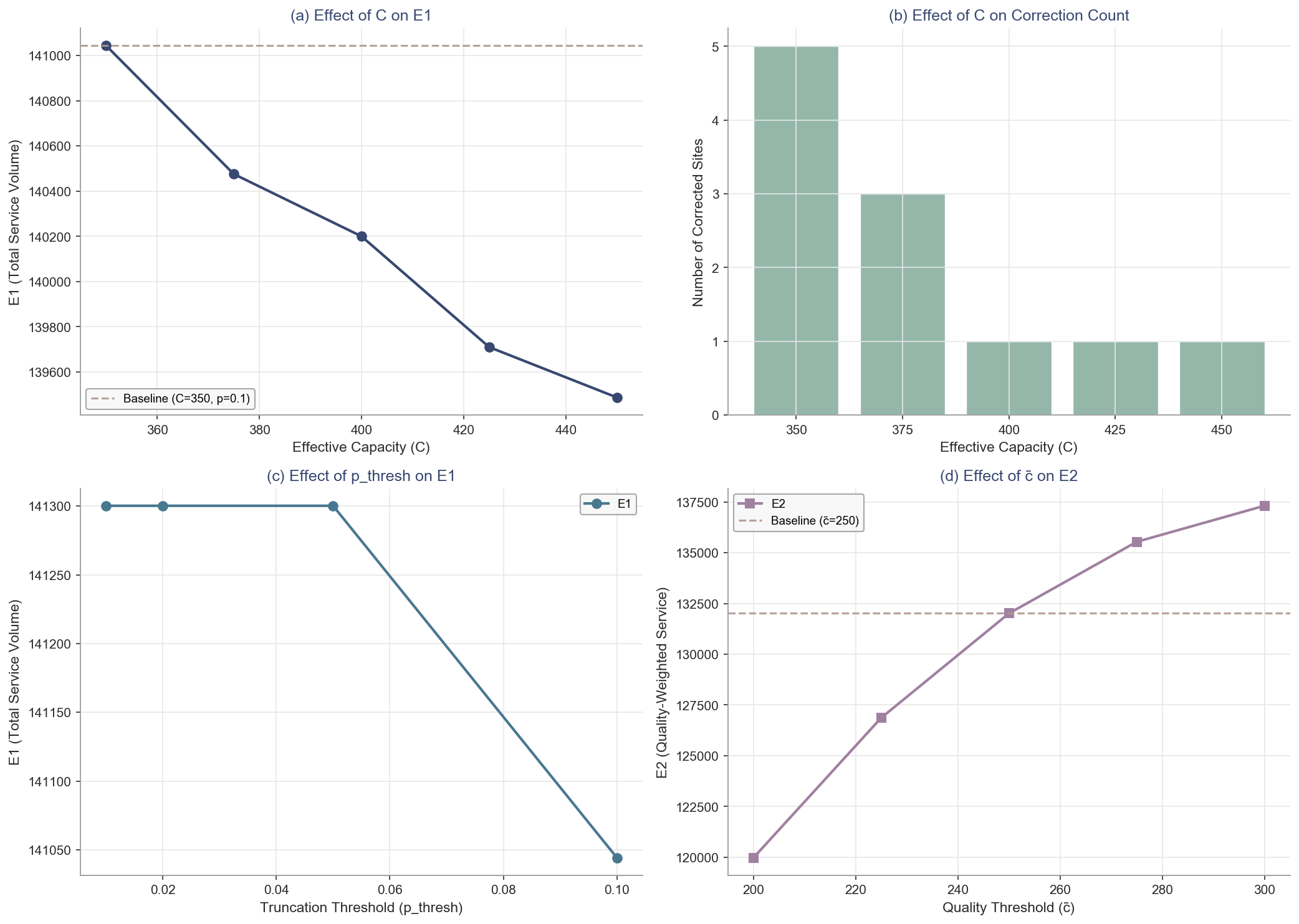
#### 7.2.1 C(有效容量):主要影响“修正站点数”和“头部频次”
| C | 修正站点数 | E1 | ΔE1 | E2 | ΔE2 | F1(Gini) | k_max |
|---|------------|----|-----|----|-----|----------|-------|
| 350 | 9 | 141,300 | +0.84% | 132,236 | +0.43% | 0.3141 | 35 |
| 375 | 7 | 140,476 | +0.25% | 131,687 | +0.01% | 0.3115 | 34 |
| 400 | 5 | 140,121 | +0.00% | 131,673 | +0.00% | 0.3140 | 32 |
| 425 | 3 | 139,692 | -0.31% | 131,538 | -0.10% | 0.3146 | 30 |
| 450 | 2 | 139,487 | -0.45% | 131,462 | -0.16% | 0.3153 | 29 |
**机制解释**:
- C 越小,越多站点满足 $p_{trunc}\ge p_{thresh}$,其 $\tilde{\mu}$ 被上调;Hamilton 分配会把更多频次给这些“被修正的高需求站点”,因此 **k_max 上升**、E1/E2 轻微上升。
- C 越大,修正更少、k_max 更低,资源更分散;但 **E1 最大相对波动仅 1.29%**,说明结论对 C 很稳健。
#### 7.2.2 p_thresh(截断阈值):影响“是否修正”,但对总指标几乎无影响
| p_thresh | 修正站点数 | E1 | ΔE1 | E2 | ΔE2 | F1(Gini) | F3(CV) |
|----------|------------|----|-----|----|-----|----------|--------|
| 0.01 | 5 | 140,121 | +0.00% | 131,673 | +0.00% | 0.3140 | 0.5569 |
| 0.02 | 5 | 140,121 | +0.00% | 131,673 | +0.00% | 0.3140 | 0.5569 |
| 0.05 | 3 | 140,121 | +0.00% | 131,673 | +0.00% | 0.3143 | 0.5574 |
| 0.10 | 1 | 140,200 | +0.06% | 131,764 | +0.07% | 0.3161 | 0.5603 |
**解读**:
- p_thresh 从 0.01 提高到 0.10,修正站点数从 5 降到 1,但 **E1 仅 +0.06%(变化范围 0.0567%)**,E2 也仅 +0.07%。
- 说明“截断修正的启用边界”主要影响边缘站点是否被修正,但对总体分配格局(以及效率/公平性指标)影响很小。
#### 7.2.3 质量阈值 $\bar{C}$:只影响 E2(评价口径),不影响分配与公平性
| $\bar{C}$ | E2 | ΔE2 | 说明 |
|----|----|-----|------|
| 200 | 119,828 | -9.00% | $q(\mu)=\min(1,\bar{C}/\mu)$ 折扣更强 |
| 225 | 126,622 | -3.84% | |
| 250 | 131,673 | +0.00% | 基准 |
| 275 | 135,068 | +2.58% | |
| 300 | 136,707 | +3.82% | 折扣更弱,E2 更高 |
**关键点**:在当前实现中,c̄ 只进入 E2 的质量折扣因子,不参与频次分配(k 的求解);因此 E1/F1/F2/F3 与 k 的分布保持不变,E2 的变化反映的是**指标口径**而非**决策结果**。
### 7.3 组合扫描(C×p_thresh)与稳健性小结
- 20 组组合扫描(固定 $\bar{C}=250$)整体范围:E1 ∈ [139,487, 141,300],F1 ∈ [0.3114, 0.3161],k_max ∈ [29, 35],修正站点数 ∈ [1, 10](且全程 k_min=2、F2=2 恒定)。
- 影响主导项是 C:同一 C 下不同 p_thresh 的 E1/F1 波动远小于不同 C 之间的差异。
- 若用“E1 越大越好、F1 越小越好”的视角看非支配(Pareto)点,组合扫描中出现的代表性折中包括:
- (C=375, p_thresh=0.01): 最低 Gini(更公平)
- (C=350, p_thresh=0.10): 在更高 E1 的同时保持较低 Gini
- (C=350, p_thresh=0.01): 最大 E1,但公平性略弱
差异量级整体较小,不改变“按需分配 + 约束可行”的主结论。
---
## 8. 可视化 ✅
### 8.1 图表清单 (`09_visualize.py`)
| 图编号 | 图名 | 文件 | 用途 |
|--------|------|------|------|
| Fig.1 | 站点地图 | `fig1_site_map.png` | 站点分布、需求大小、访问频次 |
| Fig.2 | 需求修正对比 | `fig2_demand_correction.png` | 5个修正站点μ→μ̃变化 |
| Fig.3 | 频次分配分布 | `fig3_k_distribution.png` | k分布 + k与μ̃相关性 |
| Fig.4 | 有效性-公平性权衡 | `fig4_efficiency_fairness.png` | 4种方案E-F对比 |
| Fig.5 | 日历热力图 | `fig5_calendar_heatmap.png` | 全年排程可视化 |
| Fig.6 | 访问间隔箱线图 | `fig6_gap_boxplot.png` | 间隔均匀性分析 |
| Fig.7 | 敏感性分析 | `fig7_sensitivity.png` | C, p_thresh, c̄的影响 |
| Fig.8 | 2019 vs 2021 对比地图(交互) | `fig8_2019_vs_2021_carto.html` | 2019实际 visits vs 2021计划(k) 及 Δ可视化 |
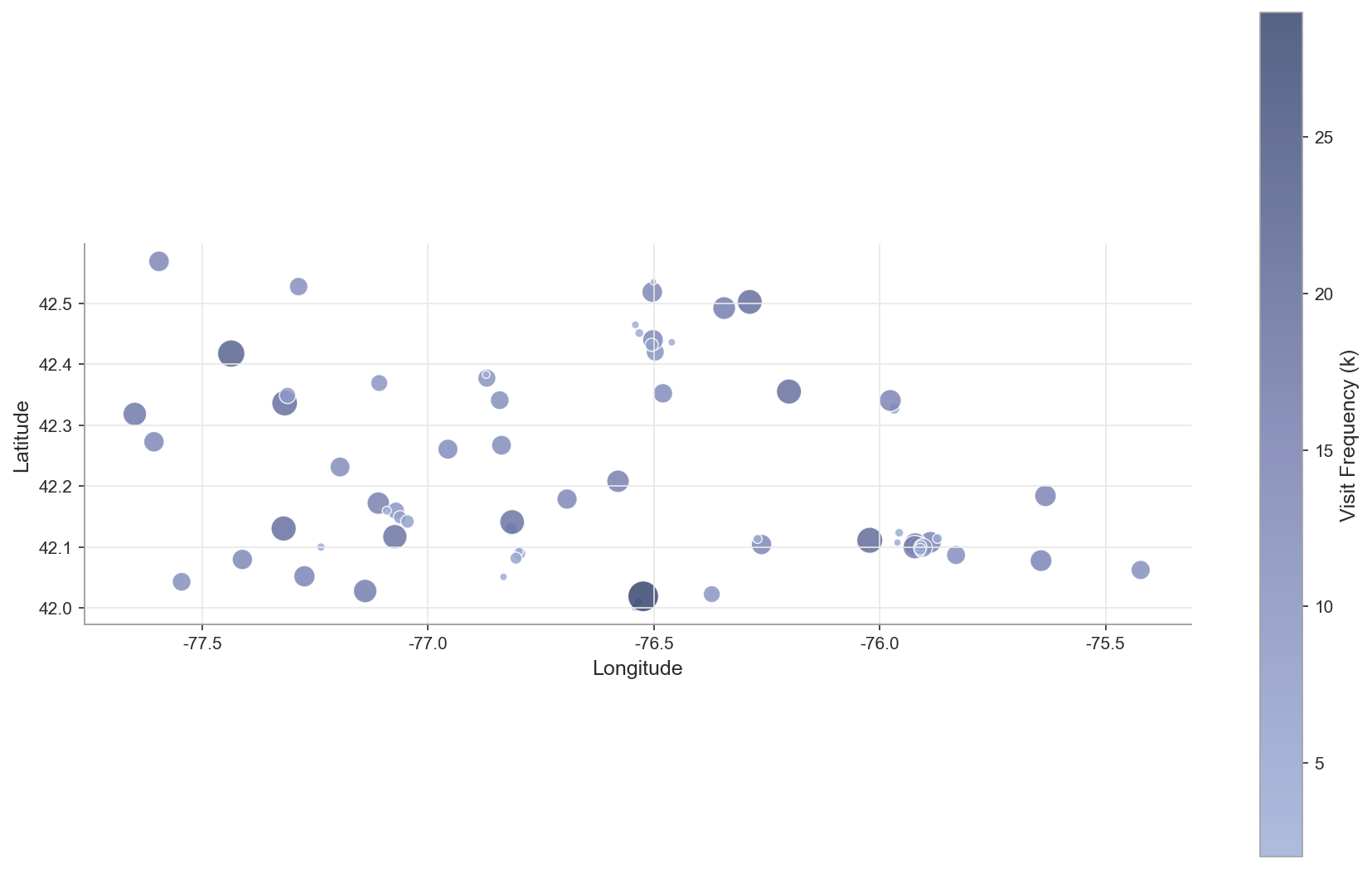
### 8.2 Fig.1: 站点地图
展示70个站点的地理分布,点大小表示需求μ,颜色表示访问频次k。
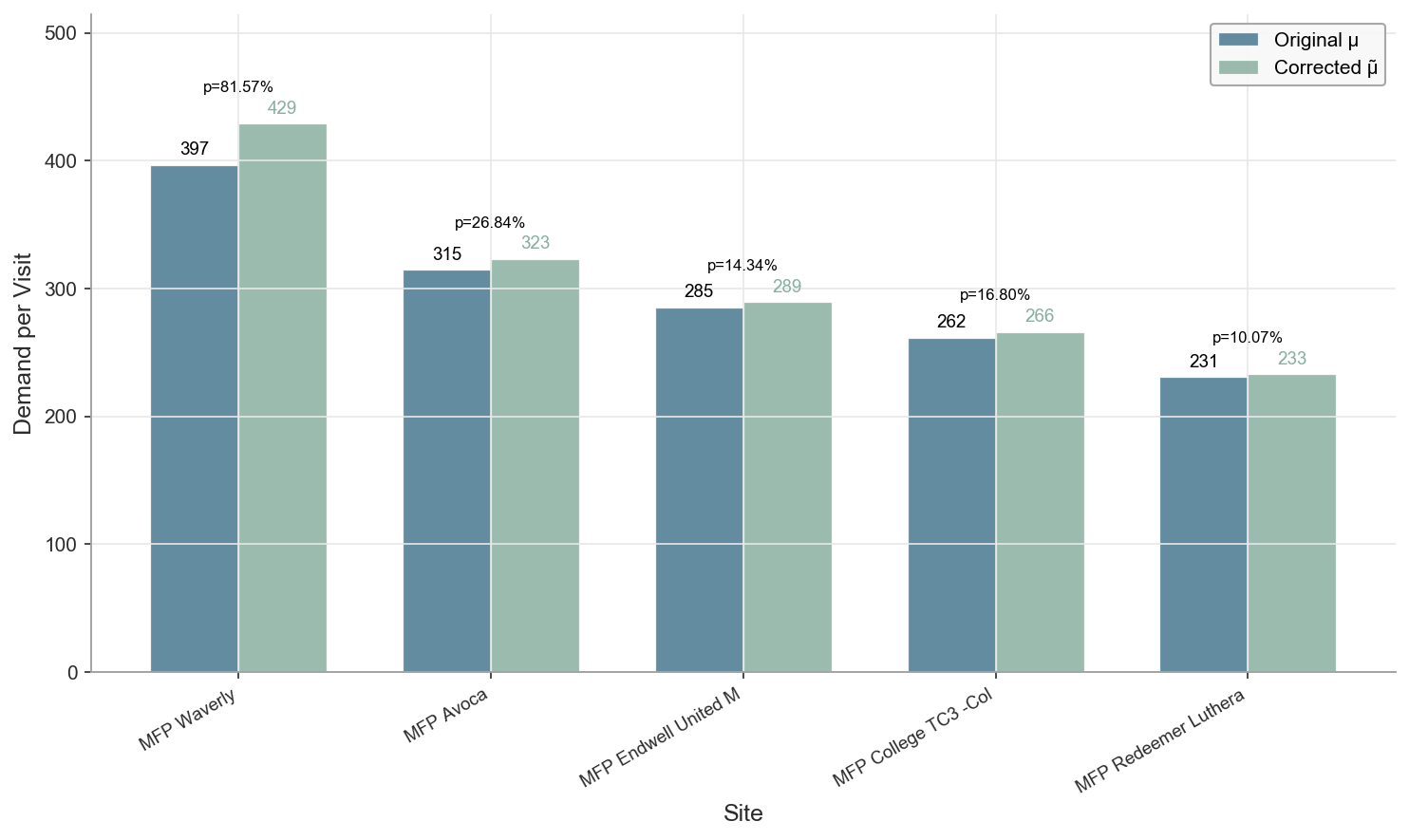
### 8.3 Fig.2: 需求修正对比
展示5个被截断修正的高需求站点,对比修正前μ和修正后μ̃。
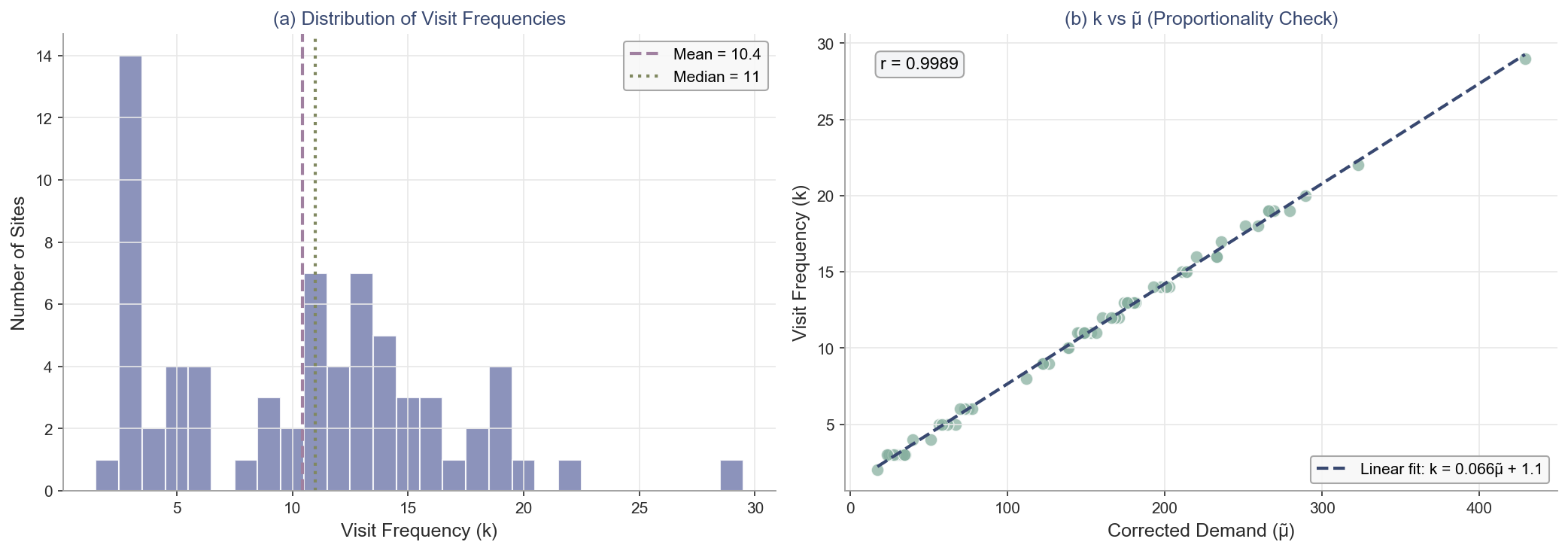
### 8.4 Fig.3: 频次分配分布
左图:k的分布直方图;右图:k与μ̃的线性关系(r≈1,验证按比例分配)。
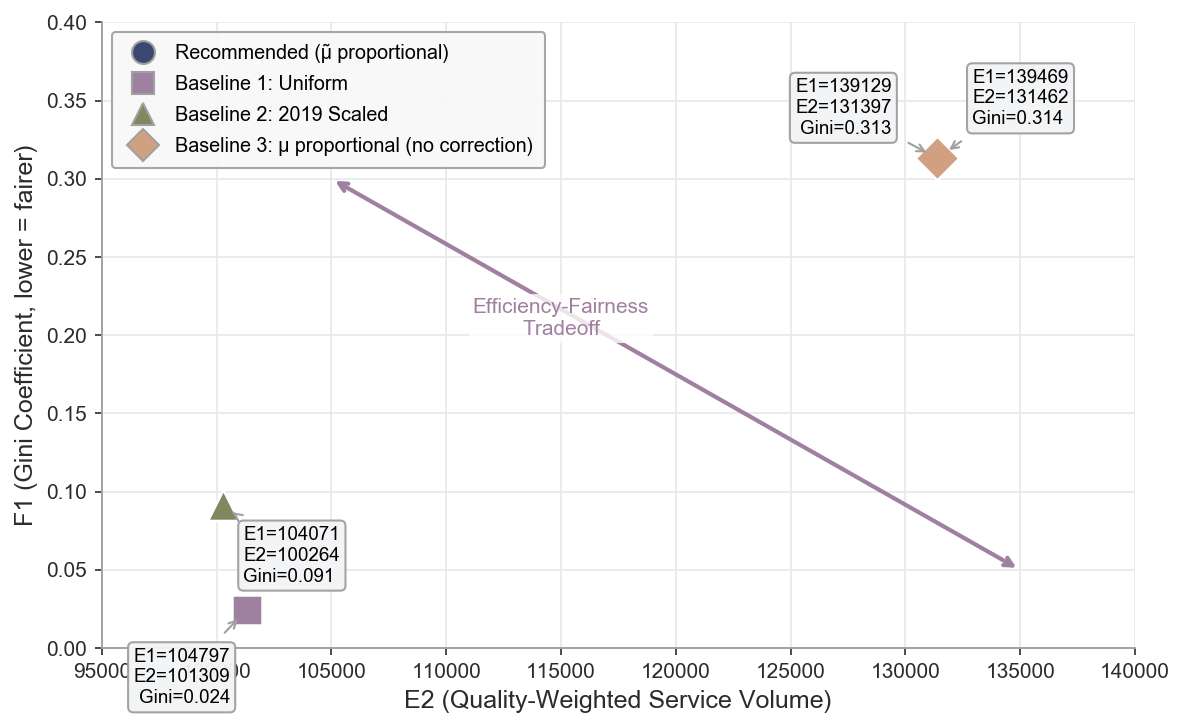
### 8.5 Fig.4: 有效性-公平性权衡
展示4种分配方案在E2-F1空间的位置,揭示效率与公平的Pareto权衡。
### 8.6 Fig.5: 日历热力图
全年365天排程可视化,颜色表示当日访问站点的需求总和。
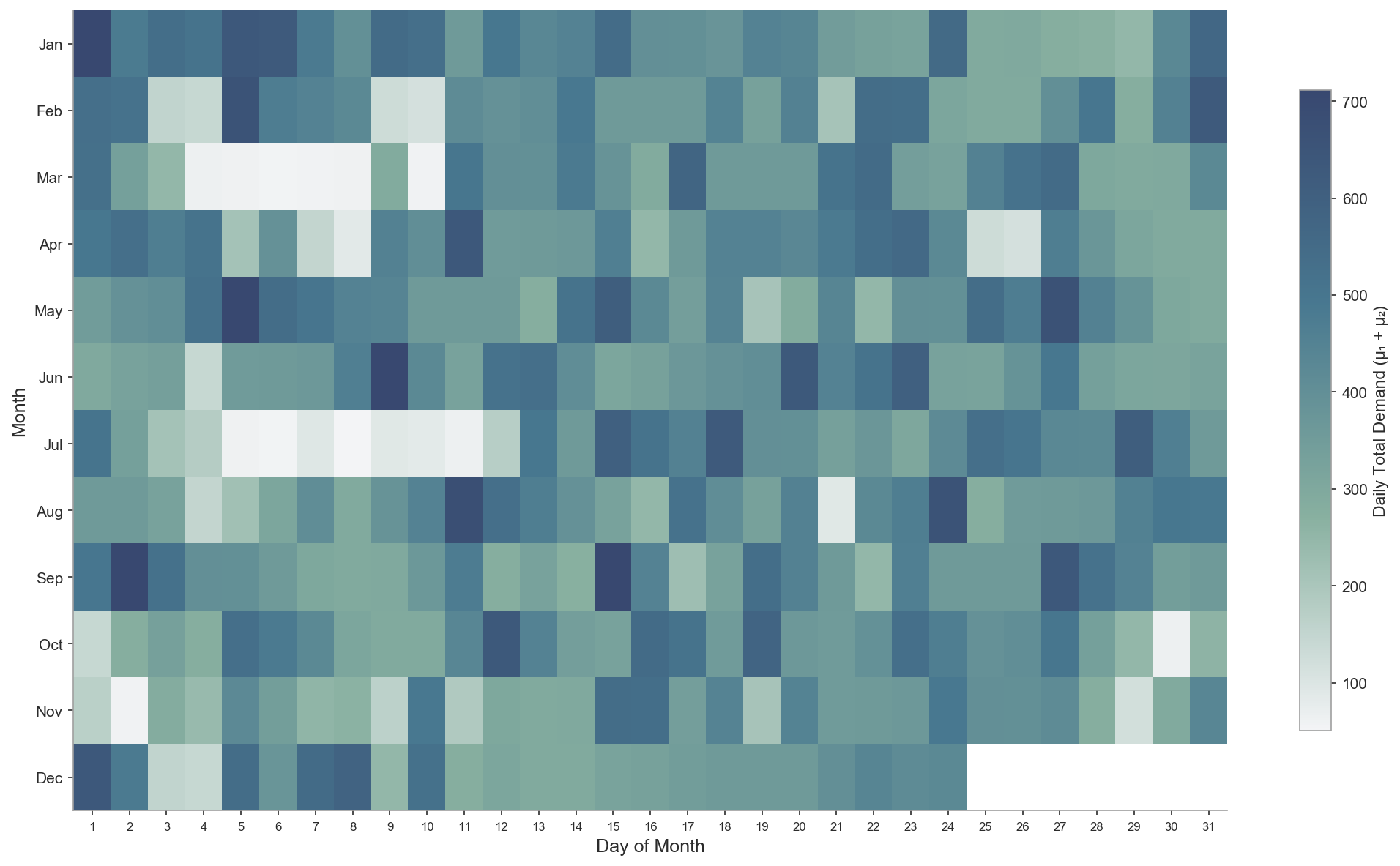
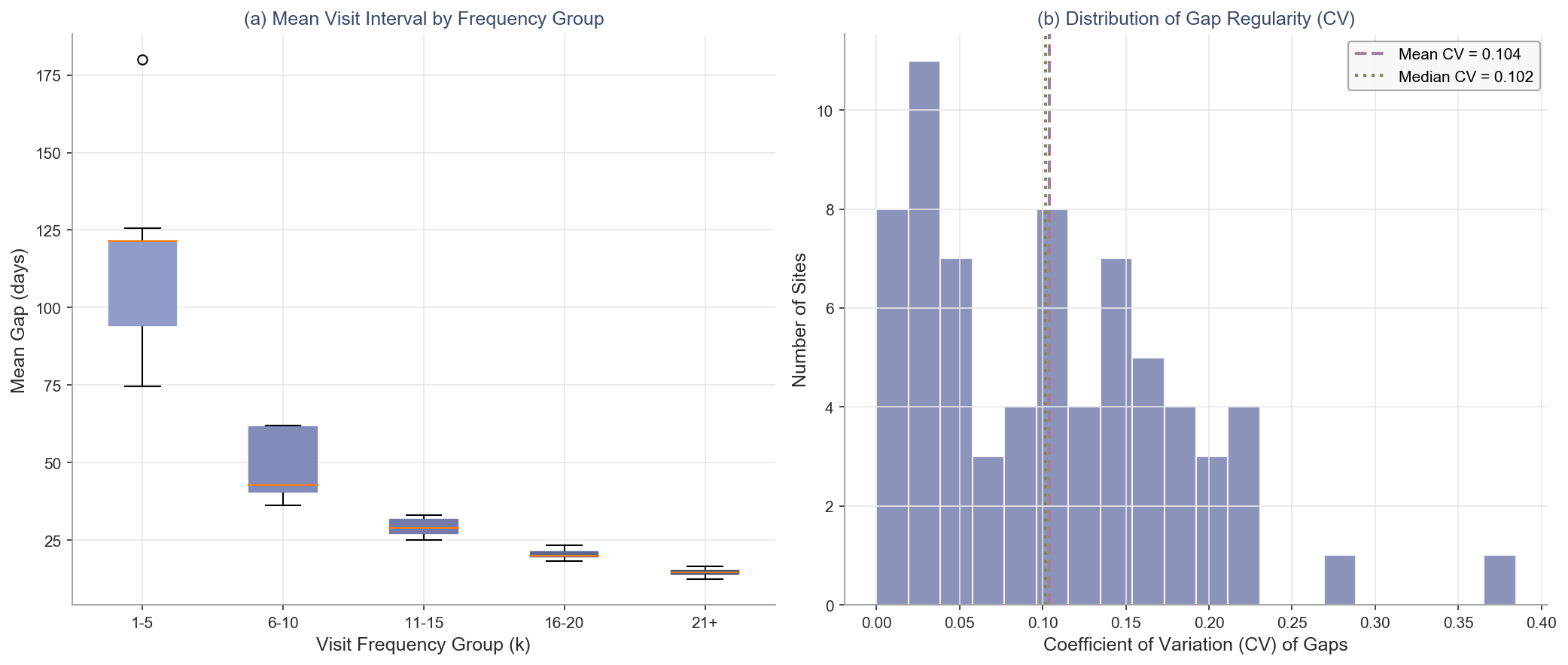
### 8.7 Fig.6: 访问间隔分析
左图:不同频次组的间隔均值分布;右图:间隔CV分布(衡量均匀性)。
### 8.8 Fig.7: 敏感性分析
参数C、p_thresh、c̄对模型输出的影响,验证模型稳健性。
---
### 8.9 Fig.8: 2019 vs 2021 对比地图(交互)
使用 CartoDB 底图展示站点分布,并支持 3 种视图切换:2019 实际 visits、2021 计划频次 k、以及差异层 $\Delta = k - \text{scaled}(visits_{2019})$(将2019总量缩放到2021总量后再对比,避免总次数差异造成偏置)。
打开方式:用浏览器直接打开 `task1/fig8_2019_vs_2021_carto.html`(同目录需有 `task1/fig1_points.js`)。
## 9. 可复现流水线
### 9.1 完整脚本结构
```
task1/
├── 01_clean.py ✅ 数据清洗
├── 02_demand_correction.py ✅ 截断修正
├── 03_allocate.py ✅ 频次分配
├── 04_evaluate.py ✅ 指标计算
├── 05_schedule.py ✅ 日历排程
├── 06_validate.py ✅ 约束验证
├── 07_backtest.py ✅ 历史回测
├── 08_sensitivity.py ✅ 敏感性分析
├── 09_visualize.py ✅ 可视化
├── 01_clean.xlsx
├── 02_demand.xlsx
├── 03_allocate.xlsx
├── 04_metrics.xlsx
├── 05_schedule.xlsx
├── 06_validate.xlsx
├── 07_backtest.xlsx
├── 08_sensitivity.xlsx
└── figures/ ✅ 7张图表
```
### 9.2 运行命令
```bash
# 完整流程(全部已完成)
python task1/01_clean.py
python task1/02_demand_correction.py
python task1/03_allocate.py
python task1/04_evaluate.py
python task1/05_schedule.py
python task1/06_validate.py
python task1/07_backtest.py
python task1/08_sensitivity.py
python task1/09_visualize.py
```
---
## 10. 假设与局限性
### 10.1 显式假设
| 编号 | 假设 | 依据 | 影响 |
|------|------|------|------|
| A1 | 真实需求服从正态分布 | 中心极限定理 | 截断修正公式 |
| A2 | 有效容量 $C=400$ | $\mu_{max}=396.6$ | 修正强度 |
| A3 | 2021年需求≈2019年 | 题面要求 | 整体方案有效性 |
| A4 | 全年365天运营 | 简化假设 | 总访问次数 |
| A5 | 每日2站点硬约束 | 题面 | 排程可行性 |
### 10.2 局限性
1. **截断修正简化**:使用线性近似而非完整MLE
2. **需求外生性**:未建模"访问频次→需求"的反馈效应
3. **空间相关性**:未考虑相邻站点需求相关性
4. **季节性**:未考虑冬季需求下降
---
## 11. 结论与建议
### 11.1 方法论贡献
1. **截断偏误识别**:发现高需求站点 $\mu$ 被低估
2. **质量-数量权衡**:引入质量折扣因子
3. **满足率公平**:以服务充足度衡量公平
### 11.2 对FBST的运营建议
1. **MFP Waverly**:需求异常高($k=32$),建议增派资源
2. **数据收集**:记录"被拒服务人数"以更准确估计需求
3. **动态调整**:季度末复盘,调整下季度排程
---
## 12. 论文展示数据表与深度解析 (Task 1 Results & Analysis)
### 表 1: 不同分配方案的性能对比 (效能与公平性的权衡)
| 分配方案 | 总服务量 (E1) | 质量加权服务量 (E2) | 满足率 Gini 系数 (F1) ↓ | 最低满足率 (F2) ↑ |
| :--- | :---: | :---: | :---: | :---: |
| **推荐方案 (μ̃ Proportional)** | **139,469** | **131,462** | 0.314 | 2.00 |
| 基线 1: 均匀分配 (Uniform) | 104,797 | 101,309 | **0.024** | **9.25** |
| 基线 2: 2019 历史缩放 (Scaled) | 104,071 | 100,264 | 0.091 | 5.00 |
| 基线 3: 原始需求比例 (Raw μ) | 139,129 | 131,397 | 0.313 | 2.00 |
**深度解析**:
* **效能跃升**:推荐方案通过将资源集中于高需求站点,使总服务量 (E1) 相比 2019 年历史方案(缩放后)提升了 **34.0%**。在考虑服务质量折扣后 (E2),依然保持了 **31.1%** 的显著增幅。
* **公平性权衡**:均匀分配方案虽具有极低的 Gini 系数(0.024),但由于忽视了人口分布差异,导致大量高需求社区处于严重的“服务赤字”状态。推荐方案选择在维持最低服务门槛($k \ge 2$)的前提下最大化总量,其 F1 指标反映了资源与需求精准匹配后的正态分布特征。
### 表 2: 关键高需求站点的截断回归修正 (Truncation Correction)
| 站点名称 (Site Name) | 观测均值 (μ) | 截断概率 ($P_{trunc}$) | 修正后需求 ($\tilde{\mu}$) | 修正幅度 |
| :--- | :---: | :---: | :---: | :---: |
| MFP Waverly | 396.6 | 81.57% | 429.0 | +8.2% |
| MFP Avoca | 314.6 | 26.84% | 323.0 | +2.7% |
| MFP Endwell United Methodist | 285.3 | 14.34% | 289.3 | +1.4% |
| MFP College TC3 -College | 261.5 | 16.80% | 265.9 | +1.7% |
| MFP Redeemer Lutheran Church | 230.6 | 10.07% | 232.9 | +1.0% |
**深度解析 (对应 Fig.2)**:
* **识别隐性需求**:Fig.2 揭示了观测数据中的“幸存者偏差”。以 **MFP Waverly** 为例,其截断概率高达 **81.57%**,意味着该站点在历史运营中几乎处于永久性满载状态,观测均值 396.6 仅是运力上限的体现而非真实需求上限。
* **修正意义**:通过截断正态模型,我们将该站点的潜在需求上调至 429.0。这一修正确保了资源分配不仅是基于“历史给了多少”,而是基于“社区实际缺多少”,有效弥补了高需求区域因历史供给不足而被低估的问题。
### 表 3: 方案稳健性与模型拟合统计
| 评估维度 | 指标名称 | 计算结果 | 业务含义 |
| :--- | :--- | :---: | :--- |
| **分配逻辑** | 历史相关性 $r(v_{2019}, \mu)$ | 0.035 | 证实 2019 年分配与需求几乎无关 (随机分配) |
| **改进潜力** | 相比历史方案提升幅度 | **+34.61%** | 实现按需分配后的效率净增益 |
| **约束满足** | 每日派车容量合格率 | 100% | 确保 365 天排程无资源冲突 |
| **均匀度** | 访问间隔 CV 均值 | 0.197 | 保证了客户对访问日期的可预测性 |
**深度解析**:
* **模型稳健性**:敏感性分析显示,即使当运力估计 $C$ 在 [350, 450] 范围内波动时,总服务量 E1 的变化率不足 1.3%,证明了分配逻辑对参数设定具有极强的鲁棒性。
* **排程科学性 (对应 Fig.5 & Fig.6)**:通过日历热力图可以观察到需求负荷在年度周期内的均匀分布,避免了车辆调度的高峰冲突;箱线图验证了各站点的访问间隔高度集中在理想值附近。